ARM AArch64 应用程序级内存模型中文翻译
Chapter B2 AArch64应用程序级内存模型(The AArch64 Application Level Memory Model)
B2.1 关于Arm内存模型(About the Arm memory model)
B2.1 关于Arm内存模型
Arm架构是一种弱有序(weakly ordered)内存架构,它允许内存访问的观察(observation)和完成(completion)顺序与程序顺序(program order)不同。本章后续各节提供了内存模型的完整定义。
本节包含以下内容:
- 地址空间(Address space)。
- 内存类型概述(Memory type overview)。
- SVE内存模型(SVE memory model)。
- SME内存模型(SME memory model)。
B2.1.1 地址空间(Address space)
地址计算使用64位寄存器执行。
然而,监管软件(supervisory software)可以将顶部八个地址位配置为用作标签(tag),如地址标记(Address tagging)中所述。如果这样配置,地址位[63:56]:
- 在确定地址是否有效时不作考虑。
- 永远不会传播到程序计数器(Program Counter)。
监管软件确定有效的地址范围。尝试访问无效地址将产生MMU故障。
指令的简单顺序执行(Simple sequential execution)可能会溢出有效地址范围。更多信息,请参见虚拟地址空间溢出(Virtual address space overflow)。
内存访问使用Mem()函数。该函数执行所需类型的访问。如果监管软件将顶部八个地址位配置为用作标签,则顶部八个地址位被忽略。
AccessType定义了不同的访问类型和属性。
注意:
- AArch64系统级内存模型(The AArch64 System Level Memory Model)和AArch64虚拟内存系统架构(The AArch64 Virtual Memory System Architecture)包含了对应用程序透明(transparent)的内存系统特性的描述,包括内存访问、地址转换、内存维护指令、对齐检查及相关的故障处理。这些章节还包含了这些操作的伪代码描述。
- 有关与内存访问相关的伪代码信息,请参见基本内存访问(Basic memory access)、非对齐内存访问(Unaligned memory access)和对齐内存访问(Aligned memory access)。
B2.1.2 内存类型概述(Memory type overview)
Arm架构提供以下互斥(mutually-exclusive)的内存类型:
| 内存类型 | 描述 |
|---|---|
| Normal(普通) | 通常用于大多数内存操作,包括读/写和只读操作。 |
| Device(设备) | Arm架构禁止对任何类型的Device内存进行推测性读取(Speculative reads)。这意味着Device内存类型适用于对读取敏感(read-sensitive)的位置(Locations)的属性。 |
| 分配给外设(peripherals)的内存映射位置通常被赋予Device内存属性。 | |
| Device内存具有额外的属性,这些属性具有以下效果: | |
| - 防止读取和写入的聚合(aggregation),保持指定内存访问的数量和大小。参见聚集(Gathering)。 | |
| - 保留对单个外设的访问顺序和同步(synchronization)要求。参见重排序(Reordering)。 | |
| - 指示写入是否可以在端点(end point)之外被确认。参见提前写入确认(Early Write Acknowledgement)。 |
有关Normal内存和Device内存的更多信息,请参见内存类型和属性(Memory types and attributes)。
注意:
早期版本的Arm架构定义了单一的Device内存类型和一种强有序(Strongly-ordered)内存类型。Device内存中的注释(Note)描述了这些内存类型如何映射到Armv8内存类型。
B2.1.3 SVE内存模型(SVE memory model)
译者注: SVE = Scalable Vector Extension(可伸缩向量扩展),是Arm AArch64架构的向量扩展指令集。
ICZFSY SVE谓词化(predicated)内存操作具有向量元素大小(vector element size)和内存元素访问大小(memory element access size)。向量元素大小指定了从向量读取和写入向量的数据量。内存元素访问大小指定了从内存读取和写入内存的数据量。
ITJQJF 向量元素大小和内存元素访问大小不需要具有相同的值。
ILGGHH 对于每个内存元素,都有一个相关联的元素地址(element address)。
SVE还在以下方面影响行为:
- 单拷贝原子性(single-copy atomicity)的要求。
- SVE内存排序放宽(SVE memory ordering relaxations)。
- 单/多寄存器加载或存储(Load or Store of Single or Multiple registers)。
- SVE操作中的字节序(Endianness)。
- 访问Device内存的SVE加载和存储。
B2.1.4 SME内存模型(SME memory model)
译者注: SME = Scalable Matrix Extension(可伸缩矩阵扩展),是Arm AArch64架构的矩阵扩展指令集。
RBQSCG SME加载/存储内存访问遵循与SVE加载/存储内存访问相同的规则。
IWWVYJ 当PE处于流式SVE模式(Streaming SVE mode)时,在以下方面对Advanced SIMD&FP指令存在放宽(relaxations):
- 流式SVE模式内存排序放宽(Streaming SVE mode memory ordering relaxations)。
- 流式SVE模式下访问Device内存的加载和存储。
B2.2 Arm架构中的原子性(Atomicity in the Arm architecture)
B2.2 Arm架构中的原子性
原子性是内存访问的一种特性,以原子访问(atomic accesses)的形式描述。Arm架构描述涉及两种类型的原子性:单拷贝原子性(single-copy atomicity)和多拷贝原子性(multi-copy atomicity)。在Arm架构中,内存访问的原子性要求取决于内存类型,以及访问是显式访问还是隐式访问。更多信息,请参见:
- 单拷贝原子性的要求(Requirements for single-copy atomicity)。
- 单拷贝原子访问的属性(Properties of single-copy atomic accesses)。
- 多拷贝原子性(Multi-copy atomicity)。
- 多拷贝原子性的要求(Requirements for multi-copy atomicity)。
- 指令的并发修改和执行(Concurrent modification and execution of instructions)。
- 使用原子指令时可能的实现限制(Possible implementation restrictions on using atomic instructions)。
有关内存类型的更多信息,请参见内存类型概述(Memory type overview)。
B2.2.1 单拷贝原子性的要求(Requirements for single-copy atomicity)
对于从某个异常级别(Exception level)产生的显式内存效应(explicit memory effects),适用以下规则:
- 由加载单个通用寄存器的加载指令生成且对齐到指令中读取大小的读操作,是单拷贝原子性的。
- 由存储单个通用寄存器的存储指令生成且对齐到指令中写入大小的写操作,是单拷贝原子性的。
- 由加载两个通用寄存器的加载对(Load Pair)指令生成的读操作,若对齐到每个寄存器的加载大小,则被视为两个单拷贝原子性读操作,每个被加载的寄存器对应一个。
- 由存储两个通用寄存器的存储对(Store Pair)指令生成的写操作,若对齐到每个寄存器的存储大小,则被视为两个单拷贝原子性写操作,每个被存储的寄存器对应一个。
- 两个32位量的加载独占对(Load-Exclusive Pair)指令和32位量的存储独占对(Store-Exclusive Pair)指令是单拷贝原子性的。
- 当使用两个64位量的加载独占/存储独占对(Load-Exclusive/Store-Exclusive pair)指令的存储独占成功时,它会对整个被更新的内存位置产生单拷贝原子性更新。
注意:
要以原子方式加载两个64位量,可以执行加载独占对/存储独占对(Load-Exclusive pair/Store-Exclusive pair)序列,读取并写回相同的值,其中存储独占对成功,并使用加载独占对读取的值。
- 当页表遍历(translation table walks)生成对页表项的读操作时,该读操作是单拷贝原子性的。
- 关于指令预取的原子性,请参见指令的并发修改和执行(Concurrent modification and execution of instructions)。
- 对SIMD和浮点寄存器中单个64位或更小量的读操作,若对齐到被加载量的大小,则被视为单拷贝原子性读操作。
- 从SIMD和浮点寄存器中单个64位或更小量的写操作,若对齐到被存储量的大小,则被视为单拷贝原子性写操作。
- 对SIMD和浮点寄存器中64位或更小元素的元素或结构体读操作(Element or Structure Reads),其中每个元素对齐到被加载元素的大小,则每个元素被视为单拷贝原子性读操作。
- 从SIMD和浮点寄存器中64位或更小元素的元素或结构体写操作(Element or Structure Writes),其中每个元素对齐到被存储元素的大小,则每个元素被视为单拷贝原子性存储操作。
- 对SIMD和浮点寄存器中128位值的读操作,若该值在内存中64位对齐,则被视为一对单拷贝原子性64位读操作。
- 从SIMD和浮点寄存器中128位值的写操作,若该值在内存中64位对齐,则被视为一对单拷贝原子性64位写操作。
- 如果实现了FEAT_LS64WB,那么由LDP(SIMD&FP)或STP(SIMD&FP)指令对两个128位SIMD和浮点寄存器的访问,在以下两个条件均满足时,被视为一个单拷贝原子性256位访问:
- 该访问在内存中为32字节对齐。
- 该访问针对的是Normal Inner Write-Back、Outer Write-Back、Cacheable、Shareable内存。
- SVE断言式加载和存储指令(SVE predicated load and store instructions)对64位或更小元素具有与SIMD加载和存储指令相同的单拷贝原子性保证。
- 对64位对齐的128位元素的SVE断言式加载或存储,被视为一对64位单拷贝原子性访问。
- SVE非断言式加载和存储指令(SVE unpredicated load and store instructions)以字节访问序列的方式执行。
- SVE非断言式加载和存储指令不保证任何大于字节的访问会作为单拷贝原子性访问执行。
- 当实现了FEAT_LS64时,对内存中64字节对齐的64字节值的单拷贝原子性加载,被视为对目标地址的原子64字节读操作。
- 当实现了FEAT_LS64时,对内存中64字节对齐的64字节值的单拷贝原子性存储,被视为对目标地址的原子64字节写操作。
- 对于非对齐内存访问,单拷贝原子性在数据访问的对齐(Alignment of data accesses)中有描述。
- 原子指令(Atomic instruction)生成的读和写操作,在数据访问的整体大小上是单拷贝原子性的。
所有其他内存访问被视为对字节的访问流,并且架构不保证不同字节访问之间的原子性。
对所有字节的访问都是单拷贝原子性的。
注意:
在AArch64状态下,来自DC ZVA的任何内存访问都不具有大于单个字节的任何量的单拷贝原子性。
如果根据这些规则,一条指令被作为一系列访问执行,那么在该序列期间可以发生异常(包括中断),无论所访问的内存类型如何。如果这些异常中的任何一个使用其首选返回地址(preferred return address)返回,则生成该访问序列的指令会被重新执行,因此在异常发生之前执行的任何访问都会被重复执行。另请参见在多访问加载或存储期间获取异步异常(Taking an asynchronous exception during a multi-access load or store)。
注意:
这些多访问指令的异常行为意味着它们不适合用于软件同步目的的内存写入。
B2.2.1.1 Armv8.4中单拷贝原子性的变化(Changes to single-copy atomicity in Armv8.4)
除了上面列出的单拷贝原子性要求之外:
在FEAT_LRCPC中引入的指令在以下所有条件都满足时是单拷贝原子性的:
- 所有被访问的字节都在同一个16字节对齐的16字节量内。
- 访问针对的是Inner Write-Back、Outer Write-Back Normal Cacheable内存。
如果实现了FEAT_LSE2,则当以下所有条件都满足时,所有加载和存储都是单拷贝原子性的:
- 访问相对于其数据大小是非对齐的,但所有被访问的字节都在一个16字节对齐的16字节量内。
- 访问针对的是Inner Write-Back、Outer Write-Back Normal Cacheable内存。
如果实现了FEAT_LSE2,则加载或存储两个64位寄存器的LDP、LDNP和STP指令在以下所有条件都满足时是单拷贝原子性的:
- 整体内存访问是16字节对齐的。
- 访问针对的是Inner Write-Back、Outer Write-Back Normal Cacheable内存。
如果实现了FEAT_LSE2,则访问少于16字节的LDP、LDNP和STP指令在以下所有条件都满足时是单拷贝原子性的:
- 所有被访问的字节都在一个16字节对齐的16字节量内。
- 访问针对的是Inner Write-Back、Outer Write-Back Normal Cacheable内存。
B2.2.2 单拷贝原子访问的属性(Properties of single-copy atomic accesses)
单拷贝原子性的内存访问指令具有以下属性:
- 对于一对重叠的单拷贝原子性存储指令,其中一个存储生成的所有重叠写入,在一致性顺序(Coherence-order)上都在另一个存储生成的对应重叠写入之后(Coherence-after)。
- 对于一个与单拷贝原子性存储指令S2重叠的单拷贝原子性加载指令L1,如果L1生成的一个重叠读取从S2生成的一个重叠写入中读取(Reads-from),则S2生成的任何重叠写入在一致性顺序上都不在L1生成的对应重叠读取之后(Coherence-after)。
更多信息,请参见形式化并发模型定义的排序要求(Ordering requirements defined by the formal concurrency model)。
B2.2.3 多拷贝原子性(Multi-copy atomicity)
在多处理器系统中,对某个内存位置的写入在以下两个条件都满足时是多拷贝原子性的:
- 对所有同一位置的所有写入都被串行化,即所有观察者以相同的顺序观察到这些写入,尽管某些观察者可能无法观察到所有写入。
- 对某个位置的读取不会返回某个写入的值,直到所有观察者都观察到该写入。
注意:
非一致性(non-coherent)的写入不是多拷贝原子性的。
B2.2.4 多拷贝原子性的要求(Requirements for multi-copy atomicity)
对于Normal内存,不要求写入是多拷贝原子性的。
对于Device内存,不要求写入是多拷贝原子性的。
Arm内存模型是”其他-多拷贝原子性”(Other-multi-copy atomic)的。更多信息,请参见外部可见性要求(External visibility requirement)。
B2.2.5 指令的并发修改和执行(Concurrent modification and execution of instructions,CMODX)
Arm架构限制了由一个执行线程执行指令的同时,另一个执行线程正在修改这些指令而无需显式同步的指令集。
指令的并发修改和执行可能导致最终指令的行为类似于在同一异常级别可执行的任何可能的指令序列。然而,如果修改前后的指令都是B、B.cond、BL、BRK、CB<cc>、CBB<cc>、CBH<cc>、CBNZ、CBZ、HVC、ISB、NOP、SMC、SVC、TBNZ、TBZ、TRCIT或UDF之一,则行为会受到更多限制。
更受限的行为是:架构保证正在被并发修改和执行的指令的行为与以下任一指令的执行一致:
- 最初预取的指令(The instruction originally fetched)。
- 修改后指令的预取(A fetch of the modified instruction)。
当更受限行为的情况不适用时,为避免不可预测(UNPREDICTABLE)或受限不可预测(CONSTRAINED UNPREDICTABLE)的行为,指令修改必须在执行前进行显式同步。所需的同步如下:
当一个PE正在修改某条指令时,其他PE不得正在执行该指令。
为确保修改后的指令可被观察到,正在写入指令的PE必须执行以下指令和操作序列:
译者注: 以下为ARM架构中实现自修改代码(self-modifying code)的标准同步序列,用于确保数据访问和指令访问之间的一致性。
1
2
3
4
5
6
7
8; 同一内部共享域内数据和指令访问的一致性示例
; 进入此代码时,<Wt>包含一个新的32位指令,
; 该指令将放置于Xn指向的Cacheable空间中的某个位置。
STR Wt, [Xn]
DC CVAU, Xn ; 按VA清除数据缓存到统一点(PoU)
DSB ISH ; 确保从缓存中清除的数据可见
IC IVAU, Xn ; 按VA使指令缓存失效到PoU
DSB ISH注意:
- 如果内存区域是非缓存(Non-cacheable)或写透缓存(Write-Through Cacheable)的,则不需要DC CVAU操作。
- 如果物理内存的内容在不同映射之间不同,更改VA到PA的映射可能导致一条指令被一个PE并发修改而被另一个PE并发执行。如果修改影响的指令不在被列为允许修改的指令范围内,则必须使用同步来避免不可预测或受限不可预测的行为。
- 在多处理器系统中,DC CVAU和IC IVAU会广播到运行该序列的PE所在内部共享域(Inner Shareable domain)内的所有PE。
当修改后的指令可被观察到时,每个正在执行修改后指令的PE必须执行ISB或执行上下文同步事件(context synchronization event)以确保执行修改后的指令:
1
ISB ; 同步预取的指令流
注意:
对于CMODX行为而言,如果某个内存写效应(Memory Write Effect)E2对位置L写入的值与L的一致性顺序中早于E2的最新内存写效应E1写入的值相同,则不认为E2对位置L处的指令进行了修改。
有关所需同步操作的更多信息,请参见数据和指令访问之间的同步和一致性问题(Synchronization and coherency issues between data and instruction accesses)。
有关指令预取引起的内存访问的信息,请参见排序关系(Ordering relations)。
B2.2.6 使用原子指令时可能的实现限制(Possible implementation restrictions on using atomic instructions)
在某些实现中以及对于某些内存类型,原子性的属性可能只能通过PE之外的功能来满足。某些系统实现可能不支持对所有内存区域的原子指令。特别地,这可以适用于:
- 系统中不支持硬件缓存一致性的任何类型内存。
- 在支持硬件缓存一致性的实现中的Device内存、非缓存内存(Non-cacheable memory)或被当作非缓存处理的内存。
在此类实现中,由系统定义:
- 原子指令相对于访问内存的其他代理(other agents)是否是原子的。
- 如果原子指令相对于访问内存的其他代理是原子的,这适用于哪些地址范围或内存类型。
具体实现可以选择将哪种内存类型视为非缓存。
架构保证原子指令是原子的内存类型有:
- Inner Shareable、Inner Write-Back、Outer Write-Back Normal内存。
- Outer Shareable、Inner Write-Back、Outer Write-Back Normal内存。
架构仅要求以此方式映射的常规内存(Conventional memory)支持此功能。
如果原子指令相对于访问内存的其他代理不是原子的,那么对此类位置执行原子指令可能产生以下一个或多个效果:
该指令生成同步外部中止(synchronous External abort)。
该指令生成系统错误中断(System Error interrupt)。
该指令生成一个由实现定义的MMU故障(IMPLEMENTATION DEFINED MMU fault),其数据中止错误状态码为ESR_ELx.DFSC = 110101。
译者注: DFSC = 110101(十进制53)对应”原子指令不支持该内存类型”的故障状态码。
对于EL1&0转换机制,如果由于第一阶段转换中定义的内存类型而不支持原子指令,或者第二阶段转换未启用,则此异常是第一阶段中止(first stage abort)并路由到EL1。否则,该异常是第二阶段中止(second stage abort)并路由到EL2。
该指令被视为NOP。
指令被执行,但不保证内存访问相对于访问内存的其他代理是原子执行的。在这种情况下,该指令还可能生成系统错误中断。
系统实现可能支持对Device内存和非缓存内存的不同区域的原子浮点内存操作指令,这些区域与其它原子指令所支持的区域不同。
B2.3 形式化并发模型定义的排序要求(Ordering requirements defined by the formal concurrency model)
B2.3 形式化并发模型定义的排序要求
当前节呈现的内容对应于形式化并发模型中所描述的内容。关系(relations)的定义,包括但不限于 Dependency-ordered-before(依赖排序之前)、Barrier-ordered-before(屏障排序之前)或 Atomic-ordered-before(原子排序之前),均从形式化并发模型中直译而来。
Arm 内存模型引入了若干关系,如下所示:
- 内在关系(Intrinsic relations);例如,内在数据依赖(Intrinsic Data Dependencies)、内在控制依赖(Intrinsic Control Dependencies)、内在顺序依赖(Intrinsic Order Dependencies)和 Translation-intrinsically-before(翻译内在之前)是源于指令语义的硬件要求。
- 之后关系(After relations);例如,Coherence-after(一致性之后)和 TLBI-after(TLBI 之后)是在特定执行中恰好以该方向取向的关系,但在不同的执行中可能以相反方向取向。
- 观察关系(Observation relations);例如,Explicit-Observed-by(显式被观察)和 TLBI-Observed-by(TLBI 被观察)构建在 After 关系之上,用以描述一次执行。
- 排序关系(Ordered relations);例如,Ordered-before(排序之前)和 TLBI-ordered-before(TLBI 排序之前)是硬件在所有执行中必须遵守的架构要求。
本节描述 Arm 内存模型中的观察和排序。它包含以下子节:
- 基本定义。
- 内在依赖关系。
- Tag-check-intrinsically-before(标签检查内在之前)。
- Translation-intrinsically-before(翻译内在之前)。
- Fetch-intrinsically-before(取指内在之前)。
- 依赖关系。
- 排序关系。
- 观察关系。
- 架构允许执行的定义。
- 显式内存效果外部可见性要求的替代表述。
有关内存访问端点排序的更多信息,请参见 Reordering(重排序)。
在 Arm 内存模型中,共享性(Shareability)内存属性指示硬件必须在一组观察者之间保证内存一致性的程度。参见 Memory types and attributes(内存类型和属性)。
Arm 架构定义了额外的内存属性和相关行为,这些内容在本手册的系统级章节中定义。参见:
- AArch64 系统级内存模型。
- AArch64 虚拟内存系统架构。
另请参见 Mismatched memory attributes(不匹配的内存属性)。
本节描述的形式化内存模型涵盖了内存系统功能的大部分(但非全部)。具体而言,以下内容在范围之内:
显式访问内存的指令的排序要求(例如:LDR、STR、SWP 等)。
- 这包括任意两个显式内存效果之间的排序要求,其中:
- 显式内存效果针对相同位置(Location),来自相同或不同的 PE。
- 一个或两个显式内存效果由原子指令生成。
- 在程序顺序中,两个显式内存效果之间存在屏障指令。
- 两个显式内存效果之间存在依赖关系。
- 并排除以下情况:
- 至少一个显式内存效果由 SVE 指令生成。
- 至少一个显式内存效果由 SME 指令生成。
- 至少一个显式内存效果由 FEAT_MOPS 添加的指令生成。
- 这包括任意两个显式内存效果之间的排序要求,其中:
与虚拟内存系统架构相关的排序要求:
- 这包括:
- 隐式 TTD 内存读取效果(Implicit TTD Memory Read Effects)。
- 当实现了 FEAT_HAF 或 FEAT_HAFDBS 时的隐式 TTD 内存写入效果(Implicit TTD Memory Write Effects)。
- 导致数据中止异常的 MMU 故障效果(MMU Fault Effects)。
- 这排除:
- 与地址转换指令相关的任何效果。
- 与指令取指的地址转换相关的任何效果。
- 属于不同转换级别或阶段的隐式 TTD 内存效果之间的排序要求。
- 与 FEAT_HDBSS 相关的排序要求。
- 与 FEAT_HACDBS 相关的排序要求。
- 这包括:
当实现 FEAT_MTE2 时与标签检查相关的排序要求。这包括:
- 由标签检查指令生成的隐式标签内存读取效果(Implicit Tag Memory Read Effects)。
- 由标签加载、标签存储、标签与数据存储以及批量分配标签访问指令生成的显式标签内存效果(Explicit Tag Memory Effects)。
- 由标签检查指令生成的 TagCheck 故障效果(TagCheck Fault Effects)。
与指令取指相关的排序要求。这包括:
- 指令取指生成的隐式指令内存读取效果(Implicit Instruction Memory Read Effects)。
- DC CVAU 效果。
- IC 效果。
- 未定义指令故障效果(Undefined Instruction Fault Effects)。
注意:
Arm 正在逐步形式化内存系统架构的许多特性,但这项工作目前尚未完成。以下项目不在范围之内:
- 与事件寄存器(Event Register)相关的排序要求。
- 与独占监视器(Exclusives monitor)相关的排序要求。
- 内存访问的端点到达(Endpoint arrival)。
- 内存访问与外设之间的交互。
- 与异步异常和错误异常相关的排序要求。
- 与通用中断控制器相关的排序要求。
- 直接和间接系统寄存器读写相关的排序要求。
- 与 FEAT_GCS 相关的排序要求。
- 与 FEAT_SPE 相关的排序要求。
- 与 FEAT_TRBE 相关的排序要求。
- 与 FEAT_RME 相关的排序要求。
- 与 RAS PE 架构相关的排序要求。
- 除 DC CVAU, Xt 指令外,DC 指令生成的 DC 效果的排序要求。
这些内容将在 Arm 架构的未来版本中逐步解决,但在此之前,所需行为在 Arm ARM 的散文和伪代码中以较不正式的方式描述。
就内存模型而言,由于指令执行生成的所有效果(Effects)均被视为由执行该指令的 PE 生成。在 Arm 内存模型范围内的指令的所有效果的列表进一步在 Effects(效果)中呈现。
在本节”形式化并发模型定义的排序要求”中,假定以下所有条件:
- 以下之一适用:
- 所有 PE 属于同一个内部共享(Inner Shareable)域,并且所有内存效果均针对内部共享或外部共享(Outer Shareable)内存,前提是没有 TLB 失效操作或其对应的 DSB 指定非共享(Non-shareable)域。
- 所有 PE 属于同一个外部共享域,并且所有内存效果均针对外部共享内存,前提是没有 TLB 失效操作或其对应的 DSB 指定非共享域或内部共享域。
- 所有 PE 属于全系统(Full system)域,并且所有内存效果均针对普通(Normal)、内部非缓存(Inner Non-Cacheable)、外部非缓存(Outer Non-Cacheable)内存或设备(Device)内存,前提是没有 TLB 失效操作。
- 所有内存效果均针对普通、内部写回(Inner Write-Back)、外部写回(Outer Write-Back)内存。”形式化并发模型定义的排序要求”中的行为也适用于针对具有普通、内部写回、外部写回以外的属性(例如,设备或内部写通(Inner Write-Through)、外部写通(Outer Write-Through))的内存的效果,只要生成该内存效果的指令的行为对该内存类型是有保证的。例如,原子指令仅在针对普通、内部写回、外部写回、可共享(Shareable)内存时才保证是原子的。针对具有普通、内部写回、外部写回以外属性的内存的效果可能需要在”形式化并发模型定义的排序要求”中指定的排序行为之外,额外的排序行为。此类额外行为在 Memory types and attributes(内存类型和属性)中描述。
- 对给定位置的所有内存效果不使用不匹配的内存属性,如 Mismatched memory attributes(不匹配的内存属性)中所述。
B2.3.1 基本定义(Basic definitions)
Arm 内存模型提供了一组定义,用于构建对允许的内存访问序列的条件。
Location(位置)
Location 是一个内存位置(Memory Location)或标签位置(Tag Location)。内存位置是与物理地址空间中的一个地址相关联的一个字节数据。标签位置是一个 4 位的 MTE 分配标签(Allocation Tag),与物理地址空间中的一个地址相关联。
Effects(效果)
指令的效果可以是:
- 寄存器效果(Register Effects)。
- 内存效果(Memory Effects)。
- 显式内存效果(Explicit Memory Effects)。
- 隐式转换表描述符(TTD)内存效果(Implicit Translation Table Descriptor (TTD) Memory Effects)。
- 硬件更新效果(Hardware Update Effects)。
- 标签内存效果(Tag Memory Effects)。
- 隐式指令内存读取效果(Implicit Instruction Memory Read Effects)。
- 屏障效果(Barrier Effects)。
- 指令取指屏障效果(Instruction Fetch Barrier Effects)。
- 条件分支和内在分支效果(Conditional Branching, and Intrinsic Branching Effects)。
- 故障效果、异常进入和异常返回效果(Fault Effects, Exception Entry, and Exception Return Effects)。
- TLBI 效果、已完成 TLBI 效果和失效范围(TLBI Effects, Completed TLBI Effects and Invalidation Scopes)。
- TLBUncacheable 效果(TLBUncacheable Effects)。
- DC CVAU 效果(DC CVAU Effects)。
- IC 效果、已完成 IC 效果(IC Effects, Completed IC Effects)。
- 空效果(Empty Effects)。
Program order(程序顺序)
当且仅当指令 I1 在程序指定的顺序中出现在指令 I2 之前时,指令 I1 的效果 E1 在程序顺序上出现在指令 I2 的效果 E2 之前。每条指令生成的每个效果都有一个唯一的效果标识符,用于在同一指令生成的各效果之间区分。
Register Effects(寄存器效果)
指令的寄存器效果是该指令的寄存器读取或寄存器写入。寄存器效果仅涉及:
- 从 R0 到 R30 的通用寄存器,不包括零寄存器。
- SVE 寄存器。
- SIMD/FP 寄存器。
- PSTATE.NZCV。
- 可读系统寄存器的直接读取。
- 可写系统寄存器的直接写入。
- 可读专用寄存器的直接读取。
- 可写专用寄存器的直接写入。
对于访问寄存器的指令,为指令读取的每个寄存器生成一个寄存器读取效果,为指令写入的每个寄存器生成一个寄存器写入效果。一条指令可以同时生成寄存器读取和写入效果。
Memory Effects(内存效果)
指令的内存效果是指令对内存的读取或写入效果。对于访问内存的指令,为指令读取的每个位置生成一个内存读取效果,为指令写入的每个位置生成一个内存写入效果。一条指令可以同时生成内存读取和写入效果。
Explicit Memory Effects(显式内存效果)
显式内存效果是由以下之一生成的内存读取或内存写入效果:
- 加载指令、存储指令、原子指令、标签和数据存储指令、DC ZVA、DC GZVA 或 STZGM;用于访问指令中以下任一项所寻址的内存位置:
- Xn|SP 操作数,加上任何适用的偏移量。
- PC 加上 <label> 参数指定的偏移量。
- 标签加载指令、标签存储指令、标签和数据存储指令、批量分配标签访问指令、DC GZVA 或 DC GVA;用于访问指令的 Xn|SP 操作数(加上任何适用的偏移量)所寻址的标签位置。
- 内存复制或内存设置指令;用于访问指令的 Xs 或 Xd 操作数所寻址的内存位置,包括指令的 Xn 操作数指定范围内的所有字节。
- 带标签设置的内存设置指令;用于访问指令的 Xs 或 Xd 操作数所寻址的标签位置,包括指令的 Xn 操作数指定范围内的所有分配标签。
- 由于 FEAT_NV2 而转换为内存效果的 MRS 或 MSR 指令;用于访问 VNCR_EL2 加上指定寄存器偏移量所寻址的内存位置。
注意:
预取内存指令不生成任何显式内存效果。
Implicit Translation Table Descriptor Memory Effects(隐式转换表描述符内存效果)
隐式转换表描述符内存效果(隐式 TTD 内存效果)是由地址转换引起的对转换表描述符的内存读取或写入效果,包括对 TTD 的访问标志(Access Flag)或脏状态(Dirty State)的硬件更新。
Hardware Update Effects(硬件更新效果)
硬件更新效果是对应于修改 TTD 的访问标志或脏状态的写入的隐式 TTD 内存写入效果。
有关访问标志或脏状态的硬件更新的更多信息,参见 Hardware management of the Access flag(访问标志的硬件管理)和 Hardware management of the dirty state(脏状态的硬件管理)。
注意:
即使在缺少相应架构执行指令的情况下,访问标志的硬件更新效果也可能发生,此时该硬件更新效果被视为自主的(autonomous)。自主硬件更新效果不受适用于架构执行指令的硬件更新效果的排序关系的约束。
Tag Memory Effects(标签内存效果)
标签内存效果是内存效果的一个子集。标签内存效果是指对标签位置的内存读取或写入效果。例如:
- LDG 和 LDGM 指令为从标签位置的读取生成显式标签内存读取效果。
- STG、STGM、STGP、DC GZVA 和 DC GVA 指令为对标签位置的写入生成显式标签内存写入效果。
- 标签检查(Tag Checked)内存访问为对标签位置的读取生成隐式标签内存读取效果,同时还生成显式数据内存效果。
Implicit Instruction Memory Read Effects(隐式指令内存读取效果)
隐式指令内存读取效果是指作为指令取指结果生成的内存读取效果。
Barrier Effects(屏障效果)
屏障指令生成屏障效果。在本章中,生成的效果以指令命名。因此,ISB 指令生成 ISB 效果,DMB 指令生成 DMB 效果,DSB 指令生成 DSB 效果。
引用 DMB 效果时使用以下约定:
- DMB FULL 效果由既不带 LD 也不带 ST 限定符的 DMB 指令生成。
- DMB LD 效果由带有 LD 限定符的 DMB 指令生成。
- DMB ST 效果由带有 ST 限定符的 DMB 指令生成。
引用 DSB 效果时使用以下约定:
- DSB FULL 效果由既不带 LD 也不带 ST 限定符的 DSB 指令生成。
- DSB LD 效果由带有 LD 限定符的 DSB 指令生成。
- DSB ST 效果由带有 ST 限定符的 DSB 指令生成。
Instruction Fetch Barrier Effects(指令取指屏障效果)
指令取指屏障效果(IFBE)由以下任一项生成:
- 上下文同步事件(Context Synchronization event)。
- 因除以下任一原因之外的任何原因生成的异常,导致的进入 ELx 的异常条目(exception entry),无论 SCTLR_ELx.EIS 的值如何:
- 未被捕获的 SVC 指令执行。
- 未被禁用的 HVC 指令执行。
- 未被捕获或禁用的 SMC 指令执行。
- BKPT 指令执行。
- BRK 指令执行。
注意:
- 如果未实现 FEAT_ExS,或者实现了 FEAT_ExS 且 SCTLR_ELx.EOS 字段为 1,则异常返回效果是 IFBE,因为它是一个上下文同步事件。
- 如果未实现 FEAT_ExS,或者实现了 FEAT_ExS 且 SCTLR_ELx.EIS 字段为 1,则上面排除的异常导致的异常条目效果是 IFBE,因为它们是上下文同步事件。
Conditional Branching, and Intrinsic Branching Effects(条件分支和内在分支效果)
当在执行流程的两个可能路径之间做出选择时,生成分支效果(Branching Effects)。分支效果代表此类决策点。
条件分支效果由条件分支指令生成,当作为评估条件的结果,做出可能影响后续其他指令执行流程的选择时。
由于翻译产生的内在分支效果发生在:当作为读取 TTD 的结果,在触发故障(例如,描述符无效)和执行物理访问之间做出选择时。内在分支效果代表此类决策点。
由于标签检查产生的内在分支效果发生在:当作为读取标签的结果,在触发故障(即由于标签检查失败)和执行物理访问之间做出选择时。内在分支效果代表此类决策点。
由于指令取指产生的内在分支效果发生在:当作为读取和解码指令的结果,在触发故障(例如,取到非法指令的结果)和继续执行有效指令之间做出选择时。内在分支效果代表此类决策点。
注意:
条件选择指令(Conditional Selection instructions)和比较并交换指令(Compare-and-Swap instructions)生成内在分支效果。
Fault Effects, Exception Entry, and Exception Return Effects(故障效果、异常进入和异常返回效果)
遇到故障的指令生成故障效果(Fault Effect)。遇到导致同步异常的故障的指令生成一个同时也是异常进入效果(Exception Entry Effect)的故障效果,例如由于读取无效 TTD 或取到非法指令。
ERET 指令生成异常返回效果(Exception Return Effect)。
由 MMU 生成的故障效果称为 MMU 故障效果(MMU Fault Effect)。有关 MMU 生成的故障的完整列表,参见 MMU fault types(MMU 故障类型)。
由失败的标签检查生成的故障效果称为 TagCheck 故障效果(TagCheck Fault Effect)。
注意:
- 遇到异步 TagCheck 故障的指令生成一个不是异常进入效果的 TagCheck 故障效果。
- 遇到同步 TagCheck 故障的指令生成一个同时也是异常进入效果的 TagCheck 故障效果。
TLBI Effects, Completed TLBI Effects and Invalidation Scopes(TLBI 效果、已完成 TLBI 效果和失效范围)
TLBI 效果由 TLBI 指令生成。
如果 TLBI 效果 E1 在程序顺序上出现在 DSB FULL 效果之前,则 E1 是一个已完成 TLBI 效果(Completed TLBI Effect)。TLBI 效果的失效范围(Invalidation scope)是一组内存效果。对于虚拟地址 x,如果 x 在 TLBI 指令的范围内,则对 x 的 TTD 的内存读取或写入效果就在 TLBI 效果的失效范围内。有关 TLBI 指令范围的完整描述,参见 TLB maintenance instruction scope(TLB 维护指令范围)。
TLBUncacheable Effects(TLBUncacheable 效果)
如果 MMU 故障效果是以下之一,则该效果是 TLBUncacheable:
- 转换故障效果(Translation Fault Effect)。
- 访问标志故障效果(Access Flag Fault Effect)。
- 地址大小故障效果(Address Size Fault Effect)。
- 转换表遍历上的同步外部中止,以至于无法确定 TTD 是否本会产生转换故障、访问标志故障或地址大小故障效果。
注意:
权限故障效果(Permission Fault Effect)不是 TLBUncacheable。
DC CVAU Effects(DC CVAU 效果)
DC CVAU 效果由 DC CVAU 指令生成。
IC Effects, Completed IC Effects(IC 效果、已完成 IC 效果)
IC 效果由 IC IALLUIS、IC IALLU 或 IC IVAU 指令生成。如果 IC 效果 E1 在程序顺序上出现在 DSB FULL 效果之前,则 E1 是一个已完成 IC 效果(Completed IC Effect)。
Empty Effects(空效果)
当由分支效果(Branching Effect)表示的决策点导致该决策不产生进一步操作时,由指令生成空效果。例如,当实现了 FEAT_MTE_ASYNC 并且标签检查故障被异步报告时,成功的标签比较生成空效果,而不是 TagCheck 故障效果。
Low-order Bits(低位比特)
地址的低位比特是在输入地址到输出地址的转换过程中保持不变的那些比特。保持不变的低位比特数量取决于转换粒度大小。
Same Low-order Bits(相同低位比特)
如果效果 E1 的地址的低位比特与效果 E2 的地址的低位比特匹配,则两个效果 E1 和 E2 具有相同低位比特。
注意:
与 MMU 故障效果相关联的地址是在 FAR_ELx 中指示的故障地址。
Effects with a valid Physical Address(具有有效物理地址的效果)
如果以下之一适用,则效果 E1 是具有有效物理地址的效果:
- E1 是一个内存效果(Memory Effect)。
- E1 是一个 DC 效果(DC Effect)。
- E1 是一个 IC 效果(IC Effect)。
注意:
在访问物理地址产生 MMU 故障的情况下,PE 不会生成相应的内存效果、DC 效果或 IC 效果。
Same Location(相同位置)
如果以下之一适用,则效果 E1 和效果 E2 针对相同位置:
- 以下所有条件适用:
- E1 是一个具有有效物理地址的效果。
- E1 不是标签内存效果。
- E1 和 E2 针对相同的物理地址。
- E2 是一个具有有效物理地址的效果。
- E2 不是标签内存效果。
- 以下所有条件适用:
- E1 是一个标签内存效果。
- E1 和 E2 针对相同的物理地址。
- E2 是一个标签内存效果。
Same Cache Line(相同缓存行)
如果满足以下条件,则效果 E1 和效果 E2 针对相同缓存行:
- E1 和 E2 是内存效果、DC CVAU 效果或 IC 效果。
- E1 和 E2 针对的 PA 位于如 Cache identification(缓存标识)节所述的相同缓存行上。
Successful Read-Modify-Write pair(成功的读-修改-写对)
如果以下所有条件适用,则两个效果 E1 和 E2 形成一个成功的读-修改-写对:
- E1 是一个内存读取效果。
- E2 是一个内存写入效果。
- E1 和 E2 针对相同位置。
- 以下之一适用:
- E1 和 E2 由同一条原子指令生成。
- E1 和 E2 由同一个成功的 Load-Exclusive/Store-Exclusive 指令对生成。
Reads-from-memory(从内存读取)
Reads-from-memory 关系将内存读取和写入效果关联到相同位置,使得每个内存读取效果在程序的执行中恰好与一个内存写入效果配对。当且仅当 E1 和 E2 针对相同位置且 E2 从 E1 获取其数据时,内存读取效果 E2 从内存读取(Reads-from-memory)内存写入效果 E1。
对于两个效果 E1 和 E2,如果以下所有条件适用:
- E1 是一个显式内存读取效果。
- E2 是一个显式内存写入效果。
- E1 在程序顺序上出现在 E2 之前。
- E1 和 E2 针对相同位置。
则 E1 从内存读取 E2 不成立。
对于两个效果 E1 和 E2,如果以下所有条件适用:
- E1 是一个显式内存读取效果。
- E2 是一个显式内存写入效果。
- E1 和 E2 形成一个成功的读-修改-写对。
则 E1 从内存读取 E2 不成立。
对于两个效果 E1 和 E2,如果以下所有条件适用:
- E1 是一个隐式标签内存读取效果。
- E2 是一个显式内存写入效果。
- E1 在程序顺序上出现在 E2 之前。
- E1 和 E2 针对相同位置。
则 E1 从内存读取 E2 不成立。
译者注:Reads-from-memory 定义了内存读取从哪个写入获取值的映射关系。上述规则排除了”先读后写同一位置”和”读-修改-写对中读从写获取值”以及”隐式标签读取后显式写入”等不合理的读取来源关系。
Coherence order(一致性顺序)
每个位置有一个按位置的一致性顺序(Coherence order)关系,该关系提供了对该位置的所有内存写入效果的一个全序,从一个表示初始值的概念性内存写入效果开始。一个位置的一致性顺序代表了对该位置的内存写入效果到达内存的顺序。
Local register read successor(局部寄存器读取后继)
如果以下所有条件适用,则效果 E2 是效果 E1 的局部寄存器读取后继:
- E1 是一个寄存器写入效果。
- E1 在程序顺序上出现在 E2 之前。
- E1 和 E2 针对相同寄存器。
- 并非以下所有条件适用:
- E1 在程序顺序上出现在 E3 之前。
- E1 和 E3 针对相同寄存器。
- E3 是一个寄存器写入效果。
- E3 在程序顺序上出现在 E2 之前。
- E3 和 E2 针对相同寄存器。
- E2 是一个寄存器读取效果。
Local memory read successor(局部内存读取后继)
如果以下所有条件适用,则效果 E2 是效果 E1 的局部内存读取后继:
- E1 是一个内存写入效果。
- E1 在程序顺序上出现在 E2 之前。
- E1 和 E2 针对相同位置。
- E2 是一个内存读取效果。
- 不存在与 E1 针对相同位置的内存写入效果 E3,使得 E1 在程序顺序上出现在 E3 之前且 E3 在程序顺序上出现在 E2 之前。
Local memory write successor(局部内存写入后继)
如果以下之一适用,则效果 E2 是效果 E1 的局部内存写入后继:
- 以下所有条件适用:
- 以下之一适用:
- E1 是一个显式内存效果。
- E1 是一个隐式标签内存读取效果。
- E1 在程序顺序上出现在 E2 之前。
- E1 和 E2 针对相同位置。
- E2 是一个显式内存写入效果。
- 以下所有条件适用:
- E1 是一个隐式 TTD 内存读取效果。
- E1 在程序顺序上出现在 E2 之前。
- E1 和 E2 针对相同位置。
- 以下之一适用:
- E2 是一个显式内存写入效果。
- E2 是一个硬件更新效果。
Coherence-before, Coherence-after(一致性之前、一致性之后)
如果内存写入效果 E1 在该位置的一致性顺序中排列在内存写入效果 E2 之前,则 E1 是在 E2 之前一致性的(Coherence-before)E2。
如果内存读取效果 E1 从内存读取(Reads-from-memory)内存写入效果 E3 且 E3 是在 E2 之前一致性的(Coherence-before),则 E1 是在内存写入效果 E2 之前一致性的。
如果 E1 是在 E2 之前一致性的,则效果 E2 是在 E1 之后一致性的(Coherence-after)。
对于两个效果 E1 和 E2,如果以下所有条件适用:
- E1 是一个显式内存写入效果。
- E2 是一个显式内存写入效果。
- E1 在程序顺序上出现在 E2 之前。
- E1 和 E2 针对相同位置。
则 E2 在 E1 之前一致性不成立。
对于两个效果 E1 和 E2,如果以下所有条件适用:
- E1 是一个显式内存写入效果。
- E2 是一个显式内存读取效果。
- E1 在程序顺序上出现在 E2 之前。
- E1 和 E2 针对相同位置。
则 E2 在 E1 之前一致性不成立。
对于两个效果 E1 和 E2,如果以下所有条件适用:
- E1 是一个显式内存写入效果。
- E2 是一个隐式标签内存读取效果。
- E1 在程序顺序上出现在 E2 之前。
- E1 和 E2 针对相同位置。
则 E2 在 E1 之前一致性不成立。
译者注:Coherence-before/after 定义了同一位置上写入效果之间的全局顺序(基于一致性顺序),以及读取效果相对于写入效果的位置关系。上述规则确保了程序顺序内的”先写后写”和”先写后读”不会在一致性顺序中被颠倒,即同一 PE 对同一位置的访问按程序顺序保持一致性。
TLBI-before, TLBI-after(TLBI 之前、TLBI 之后)
对于两个效果 E1 和 E2,当且仅当以下所有条件适用:
- E1 是一个已完成 TLBI 效果(Completed TLBI Effect)。
- E2 是一个隐式 TTD 内存读取效果。
- E2 在 E1 的失效范围内。
则以下之一且仅之一适用:
- E1 在 E2 之后(TLBI-after)(等价地,E2 在 E1 之前(TLBI-before)),或者
- E2 在 E1 之后(TLBI-after)(等价地,E1 在 E2 之前(TLBI-before))。
注意:
TLBI-after 关系列举了所有可能的对 (E1, E2),其中 E1 是一个 TLBI 效果,E2 是一个在 E1 失效范围内的隐式 TTD 内存读取效果,并且 TLBI-after 关系是非对称的。
DC-before, DC-after(DC 之前、DC 之后)
对于两个效果 E1 和 E2,如果以下所有条件适用:
- E1 是一个 DC CVAU 效果。
- E2 是一个显式内存写入效果。
- E1 和 E2 针对相同缓存行。
则以下之一适用:
- E1 在 E2 之后(DC-after)(等价地,E2 在 E1 之前(DC-before)),或者
- E2 在 E1 之后(DC-after)(等价地,E1 在 E2 之前(DC-before))。
注意:
DC-after 关系列举了所有可能的对 (E1, E2),其中 E1 是一个 DC CVAU 效果,E2 是一个显式内存写入效果,使得 E1 和 E2 针对相同缓存行,并且 DC-after 关系是非对称的。
IC-before, IC-after(IC 之前、IC 之后)
对于两个效果 E1 和 E2,当且仅当以下所有条件适用:
- E1 是一个已完成 IC 效果(completed IC Effect)。
- E2 是一个隐式指令内存读取效果。
- E1 和 E2 针对相同缓存行。
则以下之一且仅之一适用:
- E1 在 E2 之后(IC-after)(等价地,E2 在 E1 之前(IC-before)),或者
- E2 在 E1 之后(IC-after)(等价地,E1 在 E2 之前(IC-before))。
注意:
IC-after 关系列举了所有可能的对 (E1, E2),其中 E1 是一个已完成 IC 效果,E2 是一个隐式指令内存读取效果,使得 E1 和 E2 针对相同缓存行,并且 IC-after 关系是非对称的。
Single-copy-atomic grouping(单拷贝原子分组)
单拷贝原子分组将同一指令生成的显式内存效果归集在一起,此时架构要求这些显式内存效果是单拷贝原子的,如 Requirements for single-copy atomicity(单拷贝原子性要求)中所定义。例如,一个对齐的 STRH 指令生成两个显式内存写入效果,这两个效果在同一个单拷贝原子分组中。
Atomicity of Successful Read-Modify-Write pair(成功读-修改-写对的原子性)
对于两个效果 E1 和 E2,如果以下所有条件适用:
- E1 和 E2 形成一个成功的读-修改-写对。
- 存在一个显式内存写入效果 E3。
- 并非以下所有条件适用:
- E1 是一个显式内存效果。
- E1 和 E3 来自同一个 PE。
- E2 是一个显式内存效果。
- E2 和 E3 来自同一个 PE。
则以下情况不成立:E1 在 E3 之前一致性(Coherence-before)且 E3 在 E2 之前一致性。
译者注:该定义确保了成功的读-修改-写对的原子性:来自其他 PE 的写入效果不能插入到该对的读和写效果之间的一致性顺序中。
B2.3.2 内在依赖关系(Intrinsic Dependency relations)
内在依赖关系如下:
Intrinsic Data Dependency(内在数据依赖)
当且仅当以下所有条件适用时,存在从效果 E1 到效果 E2 的内在数据依赖:
- E1 不是内在分支效果。
- E1 和 E2 由同一条指令 I 生成。
- 该指令 I 的指令语义表明 E1 产生的值被 E2 消费。
注意:
即使在内在数据依赖可能被视为虚假依赖(false dependency)的情况下,这也适用。
Intrinsic Control Dependency(内在控制依赖)
当且仅当以下所有条件适用时,存在从效果 E1 到效果 E2 的内在控制依赖:
- E1 是一个内在分支效果。
- E1 和 E2 由同一条指令 I 生成。
- 该指令 I 的指令语义表明 E2 的生成是有条件的,并且基于 E1 的判定结果。
Intrinsic Order Dependency(内在顺序依赖)
当且仅当以下所有条件适用时,存在从效果 E1 到效果 E2 的内在顺序依赖:
- E1 是一个内存效果。
- E1 和 E2 由同一条指令 I 生成。
- 该指令 I 的指令语义表明 E1 在 E2 之前生成。
- 不存在从 E1 到 E2 的内在数据依赖。
- 不存在从 E1 到 E2 的内在控制依赖。
- E2 是一个内存效果。
下面列出其内在依赖关系在内存模型形式化过程中作为特殊情况出现的指令。这并不排除未来出现其他特殊情况的可能性。
B2.3.2.1 条件选择指令(Conditional Selection instructions)
以下适用于 CSEL Xd, Xn, Xm, cond 指令生成的效果。
当条件 cond 为真时,以下所有条件适用:
- Dt1:存在从 PSTATE.NZCV 的寄存器读取效果到对应于条件 cond 的内在分支效果的内在数据依赖。
- Ct1:存在从检查条件 cond 的内在分支效果到 Xn 的寄存器读取效果的内在控制依赖。
- Dt2:存在从 Xn 的寄存器读取效果到 Xd 的寄存器写入效果的内在数据依赖。
当条件 cond 为假时,以下所有条件适用:
- Df1:存在从 PSTATE.NZCV 的寄存器读取效果到对应于条件 cond 的内在分支效果的内在数据依赖。
- Cf1:存在从对应于条件 cond 的内在分支效果到 Xm 的寄存器读取效果的内在控制依赖。
- Df1:存在从 Xm 的寄存器读取效果到 Xd 的寄存器写入效果的内在数据依赖。
B2.3.2.2 比较并交换指令(Compare-and-Swap instructions)
以下适用于 CAS Xs, Xt, [Xn] 指令生成的效果。
当由 Xn 寻址的内存位置 x 的值不等于 Xs 的值时,以下之一适用:
- D1:存在从 Xn 的寄存器读取效果到由 Xn 寻址的内存位置 x 的显式内存读取效果的内在数据依赖。
- D2:存在从由 Xn 寻址的内存位置 x 的显式内存读取效果到检查内存位置 x 的内容是否等于寄存器 Xs 的内容的内在分支效果的内在数据依赖。
- D3:存在从 Xs 的寄存器读取效果到检查内存位置 x 的内容是否等于寄存器 Xs 的内容的内在分支效果的内在数据依赖。
- Df1:存在从由 Xn 寻址的内存位置 x 的显式内存读取效果到 Xs 的寄存器写入效果的内在数据依赖。
当由 Xn 寻址的内存位置 x 的值等于 Xs 的值时,以下之一适用:
- 以下所有条件适用:
- D1:存在从 Xn 的寄存器读取效果到由 Xn 寻址的内存位置 x 的显式内存读取效果的内在数据依赖。
- D2:存在从由 Xn 寻址的内存位置 x 的显式内存读取效果到检查内存位置 x 的内容是否等于寄存器 Xs 的内容的内在分支效果的内在数据依赖。
- D3:存在从 Xs 的寄存器读取效果到检查内存位置 x 的内容是否等于寄存器 Xs 的内容的内在分支效果的内在数据依赖。
- Ds1:存在从 Xn 的寄存器读取效果到由 Xn 寻址的内存位置 x 的显式内存写入效果的内在数据依赖。
- Ds2:存在从寄存器读取效果 Xt 到由 Xn 寻址的内存位置 x 的显式内存写入效果的内在数据依赖。
- Cs1:存在从检查内存位置 x 的内容是否等于寄存器 Xs 的内容的内在分支效果到由 Xn 寻址的内存位置 x 的显式内存写入效果的内在控制依赖。
- Ds31:存在从由 Xn 寻址的内存位置 x 的显式内存读取效果到 Xs 的寄存器写入效果的内在数据依赖。
- 以下所有条件适用:
- D1:存在从 Xn 的寄存器读取效果到由 Xn 寻址的内存位置 x 的显式内存读取效果的内在数据依赖。
- D2:存在从由 Xn 寻址的内存位置 x 的显式内存读取效果到检查内存位置 x 的内容是否等于寄存器 Xs 的内容的内在分支效果的内在数据依赖。
- D3:存在从 Xs 的寄存器读取效果到检查内存位置 x 的内容是否等于寄存器 Xs 的内容的内在分支效果的内在数据依赖。
- Ds1:存在从 Xn 的寄存器读取效果到由 Xn 寻址的内存位置 x 的显式内存写入效果的内在数据依赖。
- Ds2:存在从寄存器读取效果 Xt 到由 Xn 寻址的内存位置 x 的显式内存写入效果的内在数据依赖。
- Cs1:存在从检查内存位置 x 的内容是否等于寄存器 Xs 的内容的内在分支效果到由 Xn 寻址的内存位置 x 的显式内存写入效果的内在控制依赖。
- Ds3:存在从寄存器读取效果 Xs 到 Xs 的寄存器写入效果的内在数据依赖。
- Cs2:存在从检查内存位置 x 的内容是否等于寄存器 Xs 的内容的内在分支效果到 Xs 的寄存器写入效果的内在控制依赖。
B2.3.2.3 交换指令(Swap instructions)
以下所有条件适用于 SWP Xs, Xt, [Xn] 指令生成的效果:
- D1:存在从 Xn 的寄存器读取效果到由 Xn 寻址的内存位置 x 的显式内存读取效果的内在数据依赖。
- D2:存在从 Xn 的寄存器读取效果到由 Xn 寻址的内存位置 x 的显式内存写入效果的内在数据依赖。
- O1:存在从由 Xn 寻址的内存位置 x 的显式内存读取效果到由 Xn 寻址的内存位置 x 的显式内存写入效果的内在顺序依赖。
- D3:存在从由 Xn 寻址的内存位置 x 的显式内存读取效果到 Xt 的寄存器写入效果的内在数据依赖。
- D4:存在从 Xs 的寄存器读取效果到由 Xn 寻址的内存位置 x 的显式内存写入效果的内在数据依赖。
B2.3.2.4 带链接寄存器分支指令(Branch with Link to Register instructions)
以下所有条件适用于 BLR Xn 指令生成的效果:
- D1:存在从 Xn 的寄存器读取效果到该指令的分支效果的内在数据依赖。
B2.3.2.5 MTE 检查指令(MTE Checked instructions)
如果实现了 FEAT_MTE2,则带检查的 LDR Xt, [Xn] 指令具有以下额外的依赖关系:
当标签检查故障被配置为引发同步异常时,以下之一适用:
- 如果逻辑地址标签等于分配标签,则以下所有条件适用:
- Dst1:存在从由 Xn 寻址的内存位置 x 的标签位置 x 的隐式标签内存读取效果到检查 x 的分配标签是否等于 Xn 中的逻辑地址标签的内在分支效果的内在数据依赖。
- Cst1:存在从检查 x 的分配标签是否等于 Xn 中的逻辑地址标签的内在分支效果到由 Xn 寻址的内存位置 x 的显式内存读取效果的内在控制依赖。
- 如果逻辑地址标签不等于分配标签,则以下所有条件适用:
- Dsf1:存在从由 Xn 寻址的内存位置 x 的标签位置 x 的隐式标签内存读取效果到检查 x 的分配标签是否等于 Xn 中的逻辑地址标签的内在分支效果的内在数据依赖。
- Csf1:存在从检查 x 的分配标签是否等于 Xn 中的逻辑地址标签的内在分支效果到 TagCheck 故障效果的内在控制依赖。
当标签检查故障被配置为不引发同步异常时,以下之一适用:
- 如果逻辑地址标签等于分配标签,则以下所有条件适用:
- Dat1:存在从由 Xn 寻址的内存位置 x 的标签位置 x 的隐式标签内存读取效果到检查 x 的分配标签是否等于 Xn 中的逻辑地址标签的内在分支效果的内在数据依赖。
- Cat1:存在从检查 x 的分配标签是否等于 Xn 中的逻辑地址标签的内在分支效果到空效果的内在控制依赖。
- 如果逻辑地址标签不等于分配标签,则以下所有条件适用:
- Daf1:存在从由 Xn 寻址的内存位置 x 的标签位置 x 的隐式标签内存读取效果到检查 x 的分配标签是否等于 Xn 中的逻辑地址标签的内在分支效果的内在数据依赖。
- Caf1:存在从检查 x 的分配标签是否等于 Xn 中的逻辑地址标签的内在分支效果到 TagCheck 故障效果的内在控制依赖。
B2.3.3 Tag-check-intrinsically-before(标签检查内在之前)
Tag-check-before(标签检查之前)
如果以下所有条件适用,则效果 E1 在标签检查之前(Tag-check-before)效果 E2:
- E1 是一个隐式标签内存读取效果。
- 存在从 E1 到 E3 的内在数据依赖。
- E3 是一个分支效果。
- 存在从 E3 到 E2 的内在控制依赖。
- 以下之一适用:
- E2 是一个显式内存效果。
- E2 是一个 TagCheck 故障效果。
Tag-check-intrinsically-before(标签检查内在之前)
如果以下所有条件适用,则效果 E1 在标签检查内在之前(Tag-check-intrinsically-before)效果 E2:
- E1 在标签检查之前(Tag-check-before)E2。
- E2 不是一个显式内存读取效果。
B2.3.4 Translation-intrinsically-before(翻译内在之前)
如果以下所有条件适用,则效果 E1 在翻译内在之前(Translation-intrinsically-before)效果 E2:
- E1 是一个隐式 TTD 内存读取效果。
- 存在从 E1 到 E3 的内在数据依赖。
- E3 是一个分支效果。
- 存在从 E3 到 E2 的内在控制依赖。
- 以下之一适用:
- E2 是一个显式内存效果。
- E2 是一个 MMU 故障效果。
B2.3.5 Fetch-intrinsically-before(取指内在之前)
如果以下所有条件适用,则效果 E1 在取指内在之前(Fetch-intrinsically-before)效果 E2:
- E1 是一个隐式指令内存读取效果。
- 存在从 E1 到 E3 的内在数据依赖。
- E3 是一个分支效果。
- 以下之一适用:
- 存在从 E3 到 E2 的内在控制依赖。
- 以下所有条件适用:
- 存在从 E3 到 E4 的内在控制依赖。
- 存在从 E4 到 E2 的内在数据依赖。
B2.3.6 依赖关系(Dependency relations)
Dependency through registers and memory(通过寄存器和内存的依赖)
如果以下之一适用,则存在通过寄存器和内存从效果 E1 到效果 E2 的依赖:
- 以下所有条件适用:
- E1 不是由 Store-Exclusive 指令作为成功 Load-Exclusive/Store-Exclusive 对的一部分生成的。
- E2 是 E1 的局部寄存器读取后继。
- E2 是 E1 的局部内存读取后继。
- 存在从 E1 到 E2 的内在数据依赖。
- 以下所有条件适用:
- 存在通过寄存器和内存从 E1 到 E3 的依赖。
- 存在通过寄存器和内存从 E3 到 E2 的依赖。
Data dependency(数据依赖)
如果以下所有条件适用,则存在从效果 E1 到效果 E2 的数据依赖:
- E1 是一个显式内存读取效果。
- 存在通过寄存器和内存从 E1 到 E3 的依赖。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个寄存器读取效果。
- 存在从 E3 到 E2 的内在数据依赖。
- 生成 E3 和 E2 的指令的语义表明 E3 产生的值被消耗于计算 E2 写入的数据值。
- E2 是一个显式内存写入效果。
Address dependency(地址依赖)
如果以下所有条件适用,则存在从效果 E1 到效果 E2 的地址依赖:
- E1 是一个显式内存读取效果。
- 存在通过寄存器和内存从 E1 到 E3 的依赖。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个寄存器读取效果。
- 存在从 E3 到 E2 的内在数据依赖。
- 生成 E3 和 E2 的指令的语义表明 E3 产生的值被消耗于计算 E2 的位置地址。
- 以下之一适用:
- E2 是一个显式内存效果。
- E2 是一个隐式标签内存读取效果。
- E2 是一个隐式 TTD 内存读取效果。
- E2 是一个硬件更新效果。
- E2 是一个 TLBI 效果。
- E2 是一个 DC CVAU 效果。
- E2 是一个 IC IVAU 效果。
Control dependency(控制依赖)
如果以下所有条件适用,则存在从效果 E1 到效果 E2 的控制依赖:
- E1 是一个显式内存读取效果。
- 存在通过寄存器和内存从 E1 到 E3 的依赖。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个寄存器读取效果。
- 存在从 E3 到 E4 的内在数据依赖。
- E4 是一个条件分支效果。
- E4 在程序顺序上出现在 E2 之前。
Pick dependency through registers and memory(通过寄存器和内存的 Pick 依赖)
如果以下之一适用,则存在通过寄存器和内存从效果 E1 到效果 E2 的 Pick 依赖:
- 存在通过寄存器和内存从 E1 到 E2 的依赖。
- 存在从 E1 到 E2 的内在控制依赖。
- 以下所有条件适用:
- 存在通过寄存器和内存从 E1 到 E3 的 Pick 依赖。
- 存在通过寄存器和内存从 E3 到 E2 的 Pick 依赖。
Pick Basic dependency(Pick 基本依赖)
如果以下所有条件适用,则存在从效果 E1 到效果 E2 的 Pick 基本依赖:
- E1 是一个显式内存读取效果。
- 存在通过寄存器和内存从 E1 到 E2 的 Pick 依赖。
Pick Data dependency(Pick 数据依赖)
如果以下所有条件适用,则存在从效果 E1 到效果 E2 的 Pick 数据依赖:
- E1 是一个显式内存读取效果。
- 存在通过寄存器和内存从 E1 到 E3 的 Pick 依赖。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个寄存器读取效果。
- 以下之一适用:
- 存在从 E3 到 E2 的内在数据依赖。
- 以下所有条件适用:
- 存在从 E3 到 E4 的内在数据依赖。
- 存在从 E4 到 E2 的内在控制依赖。
- 生成 E3 和 E2 的指令的语义表明 E3 产生的值被消耗于计算 E2 写入的数据值。
- E2 是一个显式内存写入效果。
Pick Address dependency(Pick 地址依赖)
如果以下所有条件适用,则存在从效果 E1 到效果 E2 的 Pick 地址依赖:
- E1 是一个显式内存读取效果。
- 存在通过寄存器和内存从 E1 到 E3 的 Pick 依赖。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个寄存器读取效果。
- 存在从 E3 到 E2 的内在数据依赖。
- 生成 E3 和 E2 的指令的语义表明 E3 产生的值被消耗于计算 E2 的位置地址。
- 以下之一适用:
- E2 是一个显式内存效果。
- E2 是一个隐式标签内存读取效果。
- E2 是一个隐式 TTD 内存读取效果。
- E2 是一个硬件更新效果。
- E2 是一个 TLBI 效果。
- E2 是一个 DC CVAU 效果。
- E2 是一个 IC IVAU 效果。
Pick Control dependency(Pick 控制依赖)
如果以下所有条件适用,则存在从效果 E1 到效果 E2 的 Pick 控制依赖:
- E1 是一个显式内存读取效果。
- 存在通过寄存器和内存从 E1 到 E3 的 Pick 依赖。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个寄存器读取效果。
- 存在从 E3 到 E4 的内在数据依赖。
- E4 是一个条件分支效果。
- E4 在程序顺序上出现在 E2 之前。
Pick dependency(Pick 依赖)
如果以下所有条件适用,则存在从效果 E1 到效果 E2 的 Pick 依赖:
- 以下之一适用:
- 存在从 E1 到 E2 的 Pick 基本依赖。
- 存在从 E1 到 E2 的 Pick 地址依赖。
- 存在从 E1 到 E2 的 Pick 数据依赖。
- 存在从 E1 到 E2 的 Pick 控制依赖。
- E1 和 E2 不是由同一条指令生成的。
B2.3.7 排序关系(Ordering relations)
Explicit-hazard-ordered-before(显式冒险排序之前)
如果以下所有条件适用,则效果 E1 在显式冒险排序之前(Explicit-hazard-ordered-before)效果 E2:
- E1 是一个显式内存读取效果。
- E1 在程序顺序上出现在 E3 之前。
- E1 和 E3 针对相同位置。
- E3 是一个显式内存读取效果。
- 以下之一适用:
- E3 与 E4 属于同一个单拷贝原子分组。
- E3 和 E4 是同一个效果。
- E4 是一个显式内存读取效果。
- E4 在 E5 之前一致性的(Coherence-before)。
- E4 和 E5 来自不同的 PE。
- 以下之一适用:
- E5 是一个显式内存写入效果。
- E5 是一个硬件更新效果。
- 以下之一适用:
- E5 与 E2 属于同一个单拷贝原子分组。
- E5 和 E2 是同一个效果。
- 以下之一适用:
- E2 是一个显式内存写入效果。
- E2 是一个硬件更新效果。
注意:
当 E1 或 E2 或两者均由 SVE 指令生成时,显式冒险排序之前(Explicit-hazard-ordered-before)关系不适用。
译者注:Explicit-hazard-ordered-before 处理的是多 PE 场景下的”读后写”冒险(read-after-write hazard),即一个 PE 的读取观察到另一个 PE 的写入后,要求观察者的后续写入不能重排到被观察写入之前。这是内存模型中的一个关键排序约束。
TTD-read-ordered-before(TTD 读取排序之前)
如果以下之一适用,则效果 E1 在 TTD 读取排序之前(TTD-read-ordered-before)效果 E2:
- 以下所有条件适用:
- E1 在 E3 之前(TLBI-before)。
- E3 是一个 TLBI 效果。
- E3 在 DSB 排序之前(DSB-ordered-before)E2。
- 以下所有条件适用:
- E1 在 E3 之前(TLBI-before)。
- E3 是一个 TLBI 效果。
- E3 在指令取指屏障排序之前(Instruction-fetch-barrier-ordered-before)E2。
TLBI-ordered-before(TLBI 排序之前)
如果以下之一适用,则效果 E1 在 TLBI 排序之前(TLBI-ordered-before)效果 E2:
- E1 在 TTD 读取排序之前(TTD-read-ordered-before)E2。
- 以下所有条件适用:
- E3 在翻译内在之前(Translation-intrinsically-before)E1。
- E3 在 TTD 读取排序之前(TTD-read-ordered-before)E2。
- E3 和 E2 来自不同的 PE。
- 以下所有条件适用:
- E1 是一个隐式 TTD 内存读取效果。
- E1 在翻译内在之前(Translation-intrinsically-before)E4。
- E4 和 E5 具有相同低位比特。
- E4 在程序顺序上出现在 E5 之前。
- E3 在翻译内在之前(Translation-intrinsically-before)E5。
- E3 是一个隐式 TTD 内存读取效果。
- E1 和 E3 在相同的翻译上下文中生成。
- E3 在 TTD 读取排序之前(TTD-read-ordered-before)E2。
- E3 和 E2 来自不同的 PE。
注意:
引用”相同低位比特”的 TLBI-ordered-before 条款适用于以下情况:生成 E1 和 E4 的指令 I1 在程序顺序上出现在生成 E3 和 E5 的指令 I2 之前,并且 I1 和 I2 访问内存中重叠的字节。
Instruction-read-ordered-before(指令读取排序之前)
如果以下之一适用,则效果 E1 在指令读取排序之前(Instruction-read-ordered-before)效果 E2:
- 以下所有条件适用:
- E1 在 E3 之前(IC-before)。
- E3 是一个 IC 效果。
- E3 在 DSB 排序之前(DSB-ordered-before)E2。
- 以下所有条件适用:
- E1 在 E3 之前(IC-before)。
- E3 是一个 IC 效果。
- E3 在指令取指屏障排序之前(Instruction-fetch-barrier-ordered-before)E2。
- 以下所有条件适用:
- DIC 已实现。
- E1 在 E2 之前一致性的(Coherence-before)。
IC-ordered-before(IC 排序之前)
如果以下所有条件适用,则效果 E1 在 IC 排序之前(IC-ordered-before)效果 E2:
- E1 是一个隐式指令内存读取效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个隐式指令内存读取效果。
- E3 在指令读取排序之前(Instruction-read-ordered-before)E2。
Hazard-ordered-before(冒险排序之前)
如果以下之一适用,则效果 E1 在冒险排序之前(Hazard-ordered-before)效果 E2:
- E1 在显式冒险排序之前(Explicit-hazard-ordered-before)E2。
- E1 在 TLBI 排序之前(TLBI-ordered-before)E2。
- E1 在 IC 排序之前(IC-ordered-before)E2。
ETS-ordered-before(ETS 排序之前)
如果以下之一适用,则效果 E1 在 ETS 排序之前(ETS-ordered-before)效果 E2:
- 以下所有条件适用:
- 已实现 FEAT_ETS2。
- E1 是一个显式内存效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 TLBUncacheable 故障效果。
- E2 在翻译内在之前(Translation-intrinsically-before)E3。
- E2 是一个隐式 TTD 内存读取效果。
- 以下所有条件适用:
- 已实现 FEAT_ETS3。
- E1 是一个显式内存效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 MMU 故障效果。
- E2 在翻译内在之前(Translation-intrinsically-before)E3。
- E2 是一个隐式 TTD 内存读取效果。
- 以下所有条件适用:
- 已实现 FEAT_ETS3。
- E1 是一个显式内存效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个生成同步异常的 TagCheck 故障效果。
- E2 在标签检查内在之前(Tag-check-intrinsically-before)E3。
- E2 是一个隐式标签内存读取效果。
注意:
当 E1 由 Advanced SIMD、浮点、SVE 或 SME 指令生成时,ETS-ordered-before 关系不适用。当 E2 是为指令取指生成的隐式 TTD 内存读取效果时,它也不适用。
译者注:ETS(Early Termination of Translation Search)是 Armv8.8/v9.3 引入的特性(FEAT_ETS2/FEAT_ETS3),允许在发生 TLB 未命中时让后续显式内存访问不必等待页表遍历完成即可继续,但仍需保持正确的排序语义。
Fetch-ordered-before(取指排序之前)
如果以下所有条件适用,则效果 E1 在取指排序之前(Fetch-ordered-before)效果 E2:
- E1 是一个隐式指令内存读取效果。
- E1 在程序顺序上出现在 E2 之前。
- E2 不是一个隐式指令内存读取效果。
Same-Cache-Line-ordered-before(相同缓存行排序之前)
如果以下之一适用,则效果 E1 在相同缓存行排序之前(Same-Cache-Line-ordered-before)效果 E2:
- 以下所有条件适用:
- E1 是一个显式内存效果。
- E1 在程序顺序上出现在 E2 之前。
- E1 和 E2 针对相同缓存行。
- E2 是一个 DC CVAU 效果。
- 以下所有条件适用:
- E1 是一个 DC CVAU 效果。
- E1 在程序顺序上出现在 E2 之前。
- E1 和 E2 针对相同缓存行。
- E2 是一个显式内存效果。
- 以下所有条件适用:
- E1 是一个 DC CVAU 效果。
- E1 在程序顺序上出现在 E2 之前。
- E1 和 E2 针对相同缓存行。
- E2 是一个 DC CVAU 效果。
DSB-ordered-before(DSB 排序之前)
如果以下之一适用,则效果 E1 在 DSB 排序之前(DSB-ordered-before)效果 E2:
- 以下所有条件适用:
- 以下之一适用:
- E1 是一个内存效果。
- E1 是一个 DC CVAU 效果。
- E1 是一个 IC 效果。
- E1 是一个 TLBI 效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 DSB FULL 效果。
- E3 在程序顺序上出现在 E2 之前。
- 并非以下之一适用:
- E2 是一个隐式 TTD 内存效果。
- E2 是一个隐式指令内存读取效果。
- 以下所有条件适用:
- 已实现 FEAT_ETS2。
- 以下之一适用:
- E1 是一个内存效果。
- E1 是一个 DC CVAU 效果。
- E1 是一个 IC 效果。
- E1 是一个 TLBI 效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 DSB FULL 效果。
- E3 在程序顺序上出现在 E2 之前。
- E2 是一个隐式 TTD 内存效果。
- 以下所有条件适用:
- 以下之一适用:
- 以下所有条件适用:
- E1 是一个显式内存读取效果。
- E1 不是由目标寄存器为 WZR 或 XZR 的指令生成的。
- E1 是一个隐式标签内存读取效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 DSB LD 效果。
- E3 在程序顺序上出现在 E2 之前。
- 并非以下之一适用:
- E2 是一个隐式 TTD 内存效果。
- E2 是一个隐式指令内存读取效果。
- 以下所有条件适用:
- 已实现 FEAT_ETS2。
- E1 是一个显式内存读取效果。
- E1 不是由目标寄存器为 WZR 或 XZR 的指令生成的。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 DSB LD 效果。
- E3 在程序顺序上出现在 E2 之前。
- E2 是一个隐式 TTD 内存效果。
- 以下所有条件适用:
- E1 是一个显式内存写入效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 DSB ST 效果。
- E3 在程序顺序上出现在 E2 之前。
- 并非以下之一适用:
- E2 是一个隐式 TTD 内存效果。
- E2 是一个隐式指令内存读取效果。
- 以下所有条件适用:
- 已实现 FEAT_ETS2。
- E1 是一个显式内存写入效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 DSB ST 效果。
- E3 在程序顺序上出现在 E2 之前。
- E2 是一个隐式 TTD 内存效果。
注意:
无论是否实现了 FEAT_ETS2,当 E2 是为指令取指生成的隐式 TTD 内存读取效果时,DSB-ordered-before 关系不适用。
Instruction-fetch-barrier-ordered-before(指令取指屏障排序之前)
如果以下之一适用,则效果 E1 在指令取指屏障排序之前(Instruction-fetch-barrier-ordered-before)效果 E2:
- 以下所有条件适用:
- E1 是一个显式内存读取效果。
- 存在从 E1 到 E3 的控制依赖。
- E3 是一个指令取指屏障效果。
- E3 在程序顺序上出现在 E2 之前。
- 以下所有条件适用:
- E1 是一个显式内存读取效果。
- 存在从 E1 到 E3 的 Pick 控制依赖。
- E3 是一个指令取指屏障效果。
- E3 在程序顺序上出现在 E2 之前。
- 以下所有条件适用:
- E1 是一个显式内存读取效果。
- 存在从 E1 到 E3 的地址依赖。
- E3 是一个显式内存效果。
- E3 在程序顺序上出现在 E4 之前。
- E4 是一个指令取指屏障效果。
- E4 在程序顺序上出现在 E2 之前。
- 以下所有条件适用:
- E1 是一个显式内存读取效果。
- 存在从 E1 到 E3 的 Pick 地址依赖。
- E3 是一个显式内存效果。
- E3 在程序顺序上出现在 E4 之前。
- E4 是一个指令取指屏障效果。
- E4 在程序顺序上出现在 E2 之前。
- 以下所有条件适用:
- E1 是一个显式内存读取效果。
- 存在从 E1 到 E3 的 Pick 地址依赖。
- 以下之一适用:
- E3 在标签检查内在之前(Tag-check-intrinsically-before)E4。
- E3 在翻译内在之前(Translation-intrinsically-before)E4。
- E4 是一个指令取指屏障效果。
- E4 在程序顺序上出现在 E2 之前。
- 以下所有条件适用:
- E1 在 DSB 排序之前(DSB-ordered-before)E3。
- E3 是一个指令取指屏障效果。
- E3 在程序顺序上出现在 E2 之前。
- 以下所有条件适用:
- E1 是一个隐式 TTD 内存读取效果。
- E1 在翻译内在之前(Translation-intrinsically-before)E3。
- E3 是一个指令取指屏障效果。
- E3 在程序顺序上出现在 E2 之前。
- 以下所有条件适用:
- E1 是一个隐式标签内存读取效果。
- E1 在标签检查内在之前(Tag-check-intrinsically-before)E3。
- E3 是一个指令取指屏障效果。
- E3 在程序顺序上出现在 E2 之前。
- 以下所有条件适用:
- E1 是一个隐式 TTD 内存读取效果。
- E1 在翻译内在之前(Translation-intrinsically-before)E3。
- E3 是一个显式内存效果。
- E3 在程序顺序上出现在 E4 之前。
- E4 是一个指令取指屏障效果。
- E4 在程序顺序上出现在 E2 之前。
- 以下所有条件适用:
- E1 是一个隐式标签内存读取效果。
- E1 在标签检查之前(Tag-check-before)E3。
- E3 是一个显式内存效果。
- E3 在程序顺序上出现在 E4 之前。
- E4 是一个指令取指屏障效果。
- E4 在程序顺序上出现在 E2 之前。
Dependency-ordered-before(依赖排序之前)
如果以下之一适用,则效果 E1 在依赖排序之前(Dependency-ordered-before)效果 E2:
- 存在从 E1 到 E2 的地址依赖。
- 存在从 E1 到 E2 的数据依赖。
- 以下所有条件适用:
- 存在从 E1 到 E2 的控制依赖。
- 以下之一适用:
- E2 是一个显式内存写入效果。
- E2 是一个硬件更新效果。
- E2 是一个 TLBI 效果。
- E2 是一个 DC CVAU 效果。
- E2 是一个 IC 效果。
- 以下所有条件适用:
- 存在从 E1 到 E3 的地址依赖。
- E3 是一个显式内存效果。
- E3 在程序顺序上出现在 E2 之前。
- 以下之一适用:
- E2 是一个显式内存写入效果。
- E2 是一个硬件更新效果。
- 以下所有条件适用:
- 存在从 E1 到 E3 的地址依赖。
- E3 是一个显式内存效果。
- E2 是 E3 的局部内存读取后继。
- 以下之一适用:
- E2 是一个显式内存读取效果。
- E2 是一个隐式标签内存读取效果。
- 以下所有条件适用:
- 存在从 E1 到 E3 的数据依赖。
- E3 是一个显式内存效果。
- E2 是 E3 的局部内存读取后继。
- 以下之一适用:
- E2 是一个显式内存读取效果。
- E2 是一个隐式标签内存读取效果。
- 以下所有条件适用:
- E1 是一个隐式 TTD 内存读取效果。
- E1 在翻译内在之前(Translation-intrinsically-before)E3。
- E3 是一个显式内存效果。
- E3 在程序顺序上出现在 E2 之前。
- 以下之一适用:
- E2 是一个显式内存写入效果。
- E2 是一个硬件更新效果。
- 以下所有条件适用:
- E1 是一个隐式标签内存读取效果。
- E1 在标签检查之前(Tag-check-before)E3。
- E3 是一个显式内存效果。
- E3 在程序顺序上出现在 E2 之前。
- 以下之一适用:
- E2 是一个显式内存写入效果。
- E2 是一个硬件更新效果。
Pick-ordered-before(Pick 排序之前)
如果以下之一适用,则效果 E1 在 Pick 排序之前(Pick-ordered-before)效果 E2:
- 以下所有条件适用:
- 存在从 E1 到 E2 的 Pick 地址依赖。
- 以下之一适用:
- E2 是一个显式内存写入效果。
- E2 是一个硬件更新效果。
- E2 是一个 TLBI 效果。
- E2 是一个 DC CVAU 效果。
- E2 是一个 IC 效果。
- 存在从 E1 到 E2 的 Pick 数据依赖。
- 以下所有条件适用:
- 存在从 E1 到 E2 的 Pick 控制依赖。
- 以下之一适用:
- E2 是一个显式内存写入效果。
- E2 是一个硬件更新效果。
- E2 是一个 TLBI 效果。
- E2 是一个 DC CVAU 效果。
- E2 是一个 IC 效果。
- 以下所有条件适用:
- 存在从 E1 到 E3 的 Pick 地址依赖。
- E3 是一个显式内存效果。
- E3 在程序顺序上出现在 E2 之前。
- 以下之一适用:
- E2 是一个显式内存写入效果。
- E2 是一个硬件更新效果。
Atomic-ordered-before(原子排序之前)
当且仅当 E1 和 E2 由同一条原子指令或同一个成功的 Load-Exclusive/Store-Exclusive 指令对针对相同位置生成时,E1 和 E2 形成一个成功的读-修改-写对。
如果以下之一适用,则效果 E1 在原子排序之前(Atomic-ordered-before)效果 E2:
- 以下所有条件适用:
- E1 是一个显式内存效果。
- E1 和 E2 形成一个成功的读-修改-写对。
- E2 是一个显式内存效果。
- 以下所有条件适用:
- E1 是一个显式内存效果。
- E1 和 E3 形成一个成功的读-修改-写对。
- E2 是 E3 的局部内存读取后继。
- 以下之一适用:
- E2 是一个具有获取(Acquire)语义的显式内存读取效果。
- E2 是一个具有获取PC(AcquirePC)语义的显式内存读取效果。
- 以下所有条件适用:
- E1 是一个隐式 TTD 内存读取效果。
- E1 和 E2 形成一个成功的读-修改-写对。
- E2 是一个硬件更新效果。
Barrier-ordered-before(屏障排序之前)
如果以下之一适用,则效果 E1 在屏障排序之前(Barrier-ordered-before)效果 E2:
- 以下所有条件适用:
- 以下之一适用:
- E1 是一个显式内存效果。
- E1 是一个隐式标签内存读取效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 DMB FULL 效果。
- E3 在程序顺序上出现在 E2 之前。
- 以下之一适用:
- E2 是一个显式内存效果。
- E2 是一个隐式标签内存读取效果。
- E2 是一个 MMU 故障效果。
- 以下所有条件适用:
- E1 是一个显式内存效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 DMB FULL 效果。
- E3 在程序顺序上出现在 E2 之前。
- E2 是一个 DC CVAU 效果。
- 以下所有条件适用:
- E1 是一个 DC CVAU 效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 DMB FULL 效果。
- E3 在程序顺序上出现在 E2 之前。
- E2 是一个显式内存效果。
- 以下所有条件适用:
- E1 是一个 DC CVAU 效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 DMB FULL 效果。
- E3 在程序顺序上出现在 E2 之前。
- E2 是一个 DC CVAU 效果。
- 以下所有条件适用:
- 以下之一适用:
- 以下所有条件适用:
- E1 是一个显式效果。
- E1 是一个内存读取效果。
- E1 不是由目标寄存器为 WZR 或 XZR 的指令生成的。
- E1 是一个隐式标签内存读取效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 DMB LD 效果。
- E3 在程序顺序上出现在 E2 之前。
- 以下之一适用:
- E2 是一个显式内存效果。
- E2 是一个隐式标签内存读取效果。
- E2 是一个 MMU 故障效果。
- 以下所有条件适用:
- E1 是一个显式内存写入效果。
- E1 在程序顺序上出现在 E3 之前。
- E3 是一个 DMB ST 效果。
- E3 在程序顺序上出现在 E2 之前。
- 以下之一适用:
- E2 是一个显式内存写入效果。
- E2 是一个 MMU 故障效果。
- 以下所有条件适用:
- E1 是一个具有释放(Release)语义的显式内存写入效果。
- E3 和 E1 由一条原子指令生成。
- E3 是一个具有获取(Acquire)语义的显式内存读取效果。
- E1 在程序顺序上出现在 E2 之前。
- 以下之一适用:
- E2 是一个显式内存效果。
- E2 是一个隐式标签内存读取效果。
- E2 是一个 MMU 故障效果。
- 以下所有条件适用:
- E1 是一个具有释放(Release)语义的显式内存写入效果。
- E1 在程序顺序上出现在 E2 之前。
- E2 是一个具有获取(Acquire)语义的显式内存读取效果。
- 以下所有条件适用:
- 以下之一适用:
- E1 是一个具有获取(Acquire)语义的显式内存读取效果。
- E1 是一个具有获取PC(AcquirePC)语义的显式内存读取效果。
- E1 在程序顺序上出现在 E2 之前。
- 以下之一适用:
- E2 是一个显式内存效果。
- E2 是一个隐式标签内存读取效果。
- E2 是一个 MMU 故障效果。
- 以下所有条件适用:
- E1 是一个具有获取PC(AcquirePC)语义的显式内存读取效果。
- 存在从 E1 到 E2 的内在顺序依赖。
- E2 是一个具有获取PC(AcquirePC)语义的显式内存读取效果。
- 以下所有条件适用:
- 以下之一适用:
- E1 是一个显式内存效果。
- E1 是一个隐式标签内存读取效果。
- E1 在程序顺序上出现在 E2 之前。
- E2 是一个具有释放(Release)语义的显式内存写入效果。
- 以下所有条件适用:
- E1 是一个具有释放(Release)语义的显式内存写入效果。
- 存在从 E1 到 E2 的内在顺序依赖。
- E2 是一个具有释放(Release)语义的显式内存写入效果。
Locally-ordered-before(局部排序之前)
如果以下之一适用,则效果 E1 在局部排序之前(Locally-ordered-before)效果 E2:
- E1 在标签检查内在之前(Tag-check-intrinsically-before)E2。
- E1 在翻译内在之前(Translation-intrinsically-before)E2。
- E1 在取指内在之前(Fetch-intrinsically-before)E2。
- E1 在 ETS 排序之前(ETS-ordered-before)E2。
- E1 在取指排序之前(Fetch-ordered-before)E2。
- E1 在相同缓存行排序之前(Same-Cache-Line-ordered-before)E2。
- E1 在 DSB 排序之前(DSB-ordered-before)E2。
- E1 在指令取指屏障排序之前(Instruction-fetch-barrier-ordered-before)E2。
- E2 是 E1 的局部内存写入后继。
- 以下所有条件适用:
- E3 是 E1 的局部内存写入后继。
- E3 与 E2 属于同一个单拷贝原子分组。
- E1 在依赖排序之前(Dependency-ordered-before)E2。
- E1 在 Pick 排序之前(Pick-ordered-before)E2。
- E1 在原子排序之前(Atomic-ordered-before)E2。
- E1 在屏障排序之前(Barrier-ordered-before)E2。
- 以下所有条件适用:
- E1 在局部排序之前(Locally-ordered-before)E3。
- E3 在局部排序之前(Locally-ordered-before)E2。
Pick-locally-ordered-before(Pick 局部排序之前)
如果以下所有条件适用,则效果 E1 在 Pick 局部排序之前(Pick-locally-ordered-before)效果 E2:
- 存在从 E1 到 E3 的 Pick 依赖。
- E3 在局部排序之前(Locally-ordered-before)E2。
- E2 是一个显式内存写入效果。
Locally-hardware-required-ordered-before(局部硬件要求排序之前)
如果以下之一适用,则效果 E1 在局部硬件要求排序之前(Locally-hardware-required-ordered-before)效果 E2:
- E1 在局部排序之前(Locally-ordered-before)E2。
- E1 在 Pick 局部排序之前(Pick-locally-ordered-before)E2。
- 以下所有条件适用:
- E1 在局部硬件要求排序之前(Locally-hardware-required-ordered-before)E3。
- E3 在局部硬件要求排序之前(Locally-hardware-required-ordered-before)E2。
Hardware-required-ordered-before(硬件要求排序之前)
如果以下之一适用,则效果 E1 在硬件要求排序之前(Hardware-required-ordered-before)效果 E2:
- E1 在局部硬件要求排序之前(Locally-hardware-required-ordered-before)E2。
- E1 在冒险排序之前(Hazard-ordered-before)E2。
B2.3.8 观察关系(Observation relations)
Explicit-Observed-by(显式被观察)
如果以下之一适用,则效果 E1 被效果 E2 显式观察(Explicit-Observed-by):
- 以下所有条件适用:
- E1 是一个显式内存效果。
- E2 从内存读取(Reads-from-memory)E1。
- E1 和 E2 来自不同的 PE。
- E2 是一个显式内存效果。
- 以下所有条件适用:
- E1 是一个显式内存效果。
- E1 在 E2 之前一致性的(Coherence-before)。
- E1 和 E2 来自不同的 PE。
- E2 是一个显式内存效果。
Tag-Observed-by(标签被观察)
如果以下之一适用,则效果 E1 被效果 E2 标签观察(Tag-Observed-by):
- 以下所有条件适用:
- E1 是一个显式内存写入效果。
- E2 从内存读取(Reads-from-memory)E1。
- E1 和 E2 来自不同的 PE。
- E2 是一个隐式标签内存读取效果。
- 以下所有条件适用:
- E1 是一个隐式标签内存读取效果。
- E1 在 E2 之前一致性的(Coherence-before)。
- E1 和 E2 来自不同的 PE。
- E2 是一个显式内存写入效果。
TLBUncacheable-coherence-before(TLBUncacheable 一致性之前)
如果以下所有条件适用,则效果 E1 在 TLBUncacheable 一致性之前(TLBUncacheable-coherence-before)效果 E2:
- E1 是一个隐式 TTD 内存读取效果。
- E1 在翻译内在之前(Translation-intrinsically-before)E3。
- E3 是一个 TLBUncacheable 故障效果。
- E1 在 E2 之前一致性的(Coherence-before)。
- 以下之一适用:
- E2 是一个显式内存写入效果。
- E2 是一个硬件更新效果。
Hardware-Update-coherence-before(硬件更新一致性之前)
如果以下所有条件适用,则效果 E1 在硬件更新一致性之前(Hardware-Update-coherence-before)效果 E2:
- E1 是一个显式内存读取效果。
- E1 在 E2 之前一致性的(Coherence-before)。
- E2 是一个硬件更新效果。
TLBI-coherence-before(TLBI 一致性之前)
如果以下所有条件适用,则效果 E1 在 TLBI 一致性之前(TLBI-coherence-before)效果 E2:
- E1 是一个 TLBI 效果。
- E1 在 E3 之前(TLBI-before)。
- E3 是一个隐式 TTD 内存读取效果。
- E3 在 E2 之前一致性的(Coherence-before)。
- E2 是一个内存写入效果。
TTD-Observed-by(TTD 被观察)
如果以下之一适用,则效果 E1 被效果 E2 TTD 观察(TTD-Observed-by):
- 以下所有条件适用:
- E1 是一个隐式 TTD 内存效果。
- E2 从内存读取(Reads-from-memory)E1。
- 以下所有条件适用:
- E2 从内存读取(Reads-from-memory)E1。
- E2 是一个隐式 TTD 内存效果。
- E1 在 TLBUncacheable 一致性之前(TLBUncacheable-coherence-before)E2。
- E1 在硬件更新一致性之前(Hardware-Update-coherence-before)E2。
- 以下所有条件适用:
- E1 是一个硬件更新效果。
- E1 在 E2 之前一致性的(Coherence-before)。
- E2 是一个内存写入效果。
- 以下所有条件适用:
- E1 是一个内存写入效果。
- E1 在 E2 之前一致性的(Coherence-before)。
- E2 是一个硬件更新效果。
- E1 在 TLBI 一致性之前(TLBI-coherence-before)E2。
IC-coherence-before(IC 一致性之前)
如果以下之一适用,则效果 E1 在 IC 一致性之前(IC-coherence-before)效果 E2:
- 以下所有条件适用:
- 既未实现 DIC 也未实现 IDC。
- E1 是一个 IC 效果。
- E1 在 E3 之前(IC-before)。
- E3 是一个隐式指令内存读取效果。
- E3 在 E4 之前一致性的(Coherence-before)。
- E4 是一个内存写入效果。
- E4 在 E2 之前(DC-before)。
- E2 是一个 DC CVAU 效果。
- 以下所有条件适用:
- 未实现 DIC 且实现了 IDC。
- E1 是一个 IC 效果。
- E1 在 E3 之前(IC-before)。
- E3 是一个隐式指令内存读取效果。
- E3 在 E2 之前一致性的(Coherence-before)。
- E2 是一个内存写入效果。
- 以下所有条件适用:
- 已实现 DIC 和 IDC。
- E1 是一个隐式指令内存读取效果。
- E1 在 E2 之前一致性的(Coherence-before)。
- E2 是一个内存写入效果。
译者注:DIC(Data Independent of Code,代码数据无关)和 IDC(Instruction Data Cache,指令数据缓存一致性)是 Armv8.0 中引入的优化特性。DIC 表示指令缓存无需失效即可感知数据缓存中的新代码;IDC 表示数据缓存无需写回即可使指令缓存观察到新数据。
Instruction-Observed-by(指令被观察)
如果以下之一适用,则效果 E1 被效果 E2 指令观察(Instruction-Observed-by):
- 以下所有条件适用:
- E2 从内存读取(Reads-from-memory)E1。
- E2 是一个隐式指令内存读取效果。
- E1 在 E2 之前(IC-before)。
- 以下所有条件适用:
- E1 是一个 DC CVAU 效果。
- E1 在 E2 之前(DC-before)。
- E2 是一个内存写入效果。
- 以下所有条件适用:
- E1 是一个内存写入效果。
- E1 在 E2 之前(DC-before)。
- E2 是一个 DC CVAU 效果。
- E1 在 IC 一致性之前(IC-coherence-before)E2。
Observed-by(被观察)
如果以下之一适用,则效果 E1 被效果 E2 观察(Observed-by):
- E1 被显式观察(Explicit-Observed-by)E2 或与 E2 属于同一个单拷贝原子分组的效果。
- E1 被标签观察(Tag-Observed-by)E2 或与 E2 属于同一个单拷贝原子分组的效果。
- E1 被 TTD 观察(TTD-Observed-by)E2。
- E1 被指令观察(Instruction-Observed-by)E2。
B2.3.9 架构允许执行的定义(Definition of an Architecturally Allowed Execution)
架构允许的执行(Architecturally Allowed Execution)必须满足外部可见性要求(External visibility requirement),该要求以一个称为 Ordered-before(排序之前)的排序关系来表述。不满足外部可见性要求的执行是架构禁止的执行(Architecturally Forbidden Execution)。
Ordered-before(排序之前)
如果以下之一适用,则效果 E1 在排序之前(Ordered-before)效果 E2:
- E1 在硬件要求排序之前(Hardware-required-ordered-before)E2。
- E1 被 E2 观察(Observed-by)。
- 以下所有条件适用:
- E1 在排序之前(Ordered-before)E3。
- E3 在排序之前(Ordered-before)E2。
External visibility requirement(外部可见性要求)
外部可见性要求定义如下:架构允许的执行不得在 Ordered-before 关系中呈现循环。
特别地,对于在排序之前(Ordered-before)效果 E2 的效果 E1,外部可见性要求 E2 不被 E1 观察(Observed-by)。
译者注:外部可见性要求本质上是禁止”排序-观察循环”(Ordered-before + Observed-by 构成的循环)。这是并发内存模型的核心无环条件:如果 E1 必须在 E2 之前排序(硬件要求的),但 E2 又被观察到在 E1 之前发生,这就形成一个矛盾循环,是架构禁止的执行。该条件保证了全局完成排序(global completion order)的存在性,这是顺序一致性(sequential consistency)的关键基础。
顺序一致性(Sequential Consistency)要求所有 PE 对内存的访问存在一个全局全序,且每个 PE 的程序顺序在该全序中得以保持。Arm 内存模型通过 Ordered-before 关系的无环要求来强制这一性质。 – 译者注
B2.3.10 显式内存效果外部可见性要求的替代表述(Alternative formulations of the External visibility requirement for Explicit Memory Effects)
B2.3.10.1 额外的排序关系(Additional ordering relations)
Single-copy-atomic-ordered-before(单拷贝原子排序之前)
如果以下所有条件适用,则内存读取效果 E1 在单拷贝原子排序之前(single-copy-atomic-ordered-before)另一个内存读取效果 E2:
- E1 与 E2 属于同一个单拷贝原子分组。
- E1 从内存读取(Reads-from-memory)内存写入效果 E3。
- E1 和 E3 来自不同的 PE。
- E2 从内存读取(Reads-from-memory)内存写入效果 E4。
- E2 和 E4 来自同一个 PE。
B2.3.10.2 显式内存效果的外部完成要求(External completion requirement for Explicit Memory Effects)
显式内存效果的外部完成要求是在仅针对显式内存效果的上下文中表述外部可见性要求的一种替代方式。
Completes-before(完成之前)顺序是一个全序,对应于内存效果在系统中完成的顺序。如果以下之一适用,则效果 E1 和 E2 在 Completes-before 顺序中构成一个条目:
- 以下所有条件适用:
- E1 是一个内存写入效果。
- E2 是一个内存写入效果。
- E1 与 E2 属于同一个单拷贝原子分组。
- 以下所有条件适用:
- E1 是一个内存读取效果。
- E2 是一个内存读取效果。
- E1 与 E2 属于同一个单拷贝原子分组。
- E1 从内存读取(Reads-from-memory)内存写入效果 E3。
- E1 和 E3 来自不同的 PE。
- E2 从内存读取(Reads-from-memory)内存写入效果 E4。
- E2 和 E4 来自不同的 PE。
- 以下所有条件适用:
- E1 是一个内存读取效果。
- E2 是一个内存读取效果。
- E1 与 E2 属于同一个单拷贝原子分组。
- E1 从内存读取(Reads-from-memory)内存写入效果 E3。
- E1 和 E3 来自同一个 PE。
- E2 从内存读取(Reads-from-memory)内存写入效果 E4。
- E2 和 E4 来自同一个 PE。
- E3 与 E4 属于同一个单拷贝原子分组。
所有其他内存读取效果在 Completes-before 顺序中构成不同的条目。
Completes-before(完成之前)
如果内存读取或写入效果 E1 在 Completes-before 顺序中出现在 E2 之前,则 E1 完成之前(completes-before)E2。
从 Completes-before 顺序推导 Reads-from-memory 和 Coherence order
Reads-from-memory 关系可以通过指定每个内存读取效果从哪个内存写入效果获取其值来从 Completes-before 顺序中推导。具体而言,对于内存读取效果 E1,以下之一必须适用:
- 如果以下所有条件适用:
- 存在一个内存写入效果 E2。
- E1 是 E2 的局部内存读取后继。
- E1 在完成之前(Completes-before)E2。
- 在 Completes-before 顺序中,在 E2 与一个在程序顺序上出现在 E1 之前的针对相同位置的显式内存读取效果 E4 之间,不存在针对相同位置的内存写入效果 E3。
则必须是 E1 从内存读取(Reads-from-memory)E2。- 如果以下所有条件适用:
- 存在一个内存写入效果 E2(可能表示对位置的初始值的写入)。
- E2 和 E1 针对相同位置。
- E2 在完成之前(Completes-before)E1。
- 并非 E2 在完成之前(Completes-before)内存写入效果 E3 且 E1 是 E3 的局部内存读取后继。
- 在 Completes-before 顺序中,在 E2 和 E1 之间不存在针对相同位置的内存写入效果 E4。
- 在 Completes-before 顺序中,在 E2 与一个在程序顺序上出现在 E1 之前的针对相同位置的内存读取效果 E6 之间,不存在针对相同位置的内存写入效果 E5。
则必须是 E1 从内存读取(Reads-from-memory)E2。一致性顺序(Coherence order)可以通过将对一个内存位置的内存写入效果的一致性顺序设置为这些内存写入效果在 Completes-before 顺序中出现的顺序,来从 Completes-before 顺序中推导。每个内存位置的最终值因此由 Completes-before 顺序中每个位置的最后一个内存写入效果决定。如果给定位置不存在这样的内存写入效果,则最终值是该位置的初始值。
显式内存效果的外部完成要求
显式内存效果的外部完成要求要求:如果以下任何陈述为真,则内存效果 E1 在完成之前(Completes-before)内存效果 E2:
- E1 在局部硬件要求排序之前(Locally-hardware-required-ordered-before)E2。
- E1 是一个内存读取效果,E2 是一个内存读取效果,且 E1 在单拷贝原子排序之前(single-copy-atomic-ordered-before)E2。
B2.3.10.3 显式内存效果的外部全局完成要求(External global completion requirement for Explicit Memory Effects)
显式内存效果的外部全局完成要求是在仅针对显式内存效果的上下文中表述外部可见性要求的另一种替代方式。
Globally-completes-before(全局完成之前)顺序是一个全序,对应于内存效果在系统中完成的顺序。如果以下之一适用,则效果 E1 和 E2 在 Globally-completes-before 顺序中构成一个条目:
- 以下所有条件适用:
- E1 是一个内存写入效果。
- E2 是一个内存写入效果。
- E1 与 E2 属于同一个单拷贝原子分组。
- 以下所有条件适用:
- E1 是一个内存读取效果。
- E2 是一个内存读取效果。
- E1 与 E2 属于同一个单拷贝原子分组。
- E1 从内存读取(Reads-from-memory)内存写入效果 E3。
- E1 和 E3 来自不同的 PE。
- E2 从内存读取(Reads-from-memory)内存写入效果 E4。
- E2 和 E4 来自不同的 PE。
- 以下所有条件适用:
- E1 是一个内存读取效果。
- E2 是一个内存读取效果。
- E1 与 E2 属于同一个单拷贝原子分组。
- E1 从内存读取(Reads-from-memory)内存写入效果 E3。
- E1 和 E3 来自同一个 PE。
- E2 从内存读取(Reads-from-memory)内存写入效果 E4。
- E2 和 E4 来自同一个 PE。
- E3 与 E4 属于同一个单拷贝原子分组。
所有其他内存读取效果在 Globally-completes-before 顺序中构成不同的条目。
Globally-completes-before(全局完成之前)
如果内存读取或写入效果 E1 在 Globally-completes-before 顺序中出现在 E2 之前,则 E1 在全局完成之前(Globally-completes-before)E2。
从 Globally-completes-before 顺序推导 Reads-from-memory 和 Coherence order
Reads-from-memory 关系可以通过指定每个内存读取效果从哪个内存写入效果获取其值来从 Globally-completes-before 顺序中推导。具体而言,对于内存读取效果 E1,如果以下所有条件适用,则必须是:
- 存在内存写入效果 E2(可能表示对位置的初始值的写入)。
- E2 在全局完成之前(Globally-completes-before)E1。
- E1 和 E2 针对相同位置。
- 在 Globally-completes-before 顺序中,在 E2 和 E1 之间不存在针对相同位置的内存写入效果 E3。
- 在 Globally-completes-before 顺序中,在 E2 与一个在程序顺序上出现在 E1 之前的针对相同位置的显式内存读取效果 E5 之间,不存在针对相同位置的内存写入效果 E4。
则必须是 E1 从内存读取(Reads-from-memory)E2。
一致性顺序(Coherence order)可以通过将对一个内存位置的内存写入效果的一致性顺序设置为这些内存写入效果在 Globally-completes-before 顺序中出现的顺序,来从 Globally-completes-before 顺序中推导。每个内存位置的最终值因此由 Globally-completes-before 顺序中每个位置的最后一个内存写入效果决定。如果给定位置不存在这样的内存写入效果,则最终值是该位置的初始值。
外部全局完成要求
外部全局完成要求要求:如果以下任何陈述为真,则内存效果 E1 在全局完成之前(Globally-completes-before)内存效果 E2:
- E1 在局部硬件要求排序之前(Locally-hardware-required-ordered-before)E2,且以下之一适用:
- E1 是一个内存写入效果。
- E1 是一个内存读取效果,且以下之一适用:
- E1 从内存读取(Reads-from-memory)内存写入效果 E3,且 E1 和 E3 来自不同的 PE,或者
- E1 从内存读取(Reads-from-memory)内存写入效果 E3,E1 和 E3 来自同一个 PE,且 E3 在局部硬件要求排序之前(Locally-hardware-required-ordered-before)E2。
- E1 是一个内存读取效果,E2 是一个内存读取效果,且 E1 在单拷贝原子排序之前(single-copy-atomic-ordered-before)E2。
译者注:外部全局完成要求(External global completion requirement)与外部完成要求的区别在于,全局完成(Globally-completes-before)将写效果之间的排序要求与局部排序解耦,允许更细粒度的排序约束。这两种替代表述与 Ordered-before + Observed-by 的无环条件是等价的,但它们在不同推理场景下各有优势。外部完成要求适合将 Ordered-before 关系直接映射为完成顺序,而外部全局完成要求更适合推导全局可见性结论。
“全局完成排序”(Globally-completes-before)是 Arm 内存模型中最重要的概念之一:它定义了系统中所有内存效果(来自所有 PE)的全局完成全序。该全序要求:1) 同一 PE 的程序顺序(通过 Locally-hardware-required-ordered-before 约束)得以保持;2) 单拷贝原子分组不被拆分;3) 写效果之间在全局顺序中的相对位置可以自由安排,只要不违反一致性顺序。该全序的存在保证了多处理器环境下对内存访问结果的确定性——尽管各 PE 的访问可能被重排,但在全局完成顺序中每个内存访问都有一个确定的位置。 – 译者注
B2.4 形式化并发模型范围外的附加排序要求(Additional ordering requirements outside of the scope of the formal concurrency model)
以下各节给出了已架构化但尚未形式化的排序规则。因此,这些规则未出现在形式化并发模型中,也未出现在形式化并发模型定义的排序要求(Ordering requirements defined by the formal concurrency model)的相应转写中。这些规则将在适当的时候被整合到形式化并发模型定义的排序要求中。
B2.4.1 完成与端点排序(Completion and endpoint ordering)
对于所有内存,完成规则定义如下:
- 对于某位置的存储器读取效果(Memory Read effect)E1,当以下所有条件成立时,该效果对于某个共享域(shareability domain)而言是**完成(complete)**的:
- 该共享域内任意观察者对该同一位置的任何存储器写入效果(Memory Write Effect)都将在一致性顺序上位于 E1 之后(Coherence-after E1)。
- 与 E1 相关联的所有隐式 TTD 存储器读取效果(Implicit TTD Memory Read Effects)对于该共享域而言是完成的。
- 对于某位置的存储器写入效果(Memory Write effect)E1,当以下所有条件成立时,该效果对于某个共享域而言是完成的:
- 该共享域内任意观察者对该同一位置的任何存储器写入效果都将在一致性顺序上位于 E1 之后。
- 该共享域内任意观察者对该同一位置的任何存储器读取效果,要么读取自 E1(Reads-from E1),要么读取自一个在一致性顺序上位于 E1 之后的存储器写入效果。
- 与 E1 相关联的所有隐式 TTD 存储器读取效果对于该共享域而言是完成的。
- 当与隐式 TTD 存储器读取效果相关联的存储器访问(包括硬件更新效果(Hardware Update Effects))对于该共享域而言是完成的,并且 TLB 已更新时,该隐式 TTD 存储器读取效果对于该共享域而言是完成的。
- 当一条高速缓存维护指令(cache maintenance instruction)的存储器效果对于某个共享域而言是完成的,并且该指令产生的所有隐式 TTD 存储器读取效果对于该共享域而言也是完成的时,该指令对于该共享域而言是完成的。
- 当所有使用已被无效的 TLB 表项的存储器访问均已完成时,一条 TLB 无效化指令(TLB invalidate instruction)是完成的。
任何高速缓存或 TLB 维护指令的完成均包括其在所有受该指令以及保证该维护指令可见性所需的 DSB 操作共同影响的 PE 上的完成。
此外,对于 Device-nGnRnE 存储器,当对内存映射外设(Memory-mapped peripheral)中某位置的读取或写入满足以下两个条件时,该读取或写入才是完成的:
- 能够开始影响该内存映射外设的状态。
- 能够触发所有相关的副作用,无论这些副作用影响的是其他外设设备、PE 还是存储器。
译者注: Device-nGnRnE 是 ARM 中一种存储器类型属性组合,其中 nG(non-Gathering,不允许合并)、nR(non-Reordering,不允许重排序)、nE(non-Early write acknowledgment,不允许提前写确认),表示最严格的设备内存排序约束。
系统中观察者之间的交互并不局限于通过一致性存储器(coherent memory)中的共享变量进行通信。例如,一个观察者可以配置中断控制器以向另一个观察者触发中断,作为一种消息传递方式。这些交互通常涉及一个额外的代理,该代理定义了在不同观察者之间建立通信链路所需的指令序列。当这些交互方式与共享变量结合使用时,可以使用 DSB 指令来强制它们之间的排序。
注:
这种对 Device-nGnRnE 存储器的要求与存储器访问已到达外设端点是一致的。
注:
这些完成规则意味着,例如,一条通过 VA 操作到 PoC(Point of Coherency,一致性点)的高速缓存维护指令仅在 PoC 处的存储器已被更新后才算完成。
B2.4.1.1 外设(Peripherals)
本节定义内存映射外设(Memory-mapped peripheral)以及对该外设的读取和写入的全序关系,该全序关系定义为外设到达顺序(Peripheral arrival order):
内存映射外设(Memory-mapped peripheral)
内存映射外设占据一个实现定义(IMPLEMENTATION DEFINED)大小的内存区域,并且可以使用加载(load)和存储(store)指令进行访问。对内存映射外设的存储器效果可能产生副作用,例如导致该外设执行某个动作。从内存映射外设内地址读取的值可能与该地址最后写入的数据值不一致。因此,对内存映射外设的存储器效果可能不会出现在读取自(Reads-from)关系或一致性顺序(Coherence order)关系中。
外设到达顺序(Peripheral arrival order)
某个内存映射外设的外设到达顺序是该外设上所有存储器读取效果和存储器写入效果的一个全序关系。
对于同一外设上的存储器效果 E1 和存储器效果 E2,如果满足以下任一情况:
- 以下所有条件均成立:
- 以下任一条件成立:
- E1 针对 Device-nGnRE 存储器。
- E1 针对 Device-nGnRnE 存储器。
- 以下任一条件成立:
- E2 针对 Device-nGnRE 存储器。
- E2 针对 Device-nGnRnE 存储器。
- 以下任一条件成立:
- FEAT_XS 未实现。
- 以下所有条件均成立:
- FEAT_XS 已实现。
- E1 具有 XS 属性。
- E2 具有 XS 属性。
- 以下所有条件均成立:
- FEAT_XS 已实现。
- E1 不具有 XS 属性。
- E2 不具有 XS 属性。
- E1 在程序顺序(program-order)上位于 E2 之前。
- 以下所有条件均成立:
- 以下任一条件成立:
- E1 针对 Device-nGRE 存储器。
- E1 针对 Device-nGnRE 存储器。
- E1 针对 Device-nGnRnE 存储器。
- 以下任一条件成立:
- E2 针对 Device-nGRE 存储器。
- E2 针对 Device-nGnRE 存储器。
- E2 针对 Device-nGnRnE 存储器。
- E1 在排序顺序上位于 E2 之前(Ordered-before E2)。
- 以下所有条件均成立:
- 以下任一条件成立:
- E1 针对设备存储器(Device Memory)。
- E1 针对不可缓存的普通存储器(Non-cacheable Normal Memory)。
- 以下任一条件成立:
- E2 针对设备存储器。
- E2 针对不可缓存的普通存储器。
- E1 在屏障排序顺序上位于 E2 之前(Barrier-ordered-before E2)。
则 E1 在该外设的外设到达顺序中被插入到 E2 之前,并且不允许 E1 和 E2 合并为单个事务。否则,以下情况中恰好有一种成立:
- E1 和 E2 被合并为单个事务,并作为单个效果出现在该外设的外设到达顺序中。
- E1 在该外设的外设到达顺序中被插入到 E2 之前。
- E2 在该外设的外设到达顺序中被插入到 E1 之前。
注:
当 FEAT_XS 已实现时,如果 E1 和 E2 都针对 Device-nGnRE 存储器或 Device-nGnRnE 存储器,且 E1 和 E2 位于同一内存映射外设内,但 E1 和 E2 使用不同的 XS 属性,则到达端点的顺序不由架构定义。
译者注: Device-nGnRE 是设备内存类型,nG(不允许合并)、nR(不允许重排序)、E(允许提前写确认)。Device-nGRE 是 nG(不允许合并)、R(允许重排序)、E(允许提前写确认)。Device Memory 是广义的设备内存类型。XS(eXclusive Shareability)是用于指示共享性属性的特性。
带外排序在前(Out-of-band-ordered-before)
当且仅当以下所有条件成立时,效果 E1 被称为带外排序在效果 E2 之前(Out-of-band-ordered-before):
- E1 是一个存储器效果(Memory Effect)。
- 以下任一条件成立:
- E1 在 DSB 排序顺序上位于 E3 之前(DSB-ordered-before E3)。
- E1 在指令获取屏障排序顺序上位于 E3 之前(Instruction-fetch-barrier-ordered-before E3)。
- 存在一个以 E3 开始并间接导致 E2 产生的、实现定义的(IMPLEMENTATION DEFINED)指令序列。
- E2 是一个存储器效果。
如果效果 E1 带外排序在效果 E2 之前,则 E1 在排序顺序上位于 E2 之前(Ordered-before E2)。
注:
Arm 期望,在大多数具有早期确认(early acknowledgments)的系统中,这些确认将来自建立全局可见性(global visibility)的点或其之后的点。这样预期是为了使这些确认能够被用作实现 Arm 内存模型排序要求的机制的一部分。
译者注: 带外排序前关系(Out-of-band-ordered-before)描述的是这样一种场景:通过 DSB 或指令获取屏障与一个实现定义的间接指令序列配合,形成一种排序关系。这在处理某些外设中断或带外信号传递时使用。
B2.4.2 元数据依赖(Metadata Dependencies)
IYRYHC 以下指令的执行会为 Arm 内存模型的目的创建排序关系:
- IRG。
- PACDA。
- PACDB。
- AUTDA。
- AUTDB。
RTVHSL 如果 FEAT_MTE 已实现,则 IRG Xd,Xn,Xm 指令的执行会创建:
- 一个通过寄存器和内存产生的依赖关系(Dependency),从 Xn 的寄存器读取效果(Register Read Effect)到 Xd 的寄存器写入效果(Register Write Effect)。
- 如果当前异常级别(Exception level)未阻止分配标签访问(Allocation Tag Access),则创建一个通过寄存器和内存产生的依赖关系,从 Xm 的寄存器读取效果到 Xd 的寄存器写入效果。
译者注: MTE(Memory Tagging Extension)是 ARMv8.5 引入的内存标记扩展,IRG(Insert Random Tag)插入随机标签指令用于生成随机标签值。
RMSWTM 如果 FEAT_PAuth 已实现,则 PACDA Xd,Xn 指令的执行会创建:
- 一个通过寄存器和内存产生的依赖关系,从 Xd 的寄存器读取效果到 Xd 的寄存器写入效果。
- 如果使用 APDAKey_EL1 密钥的身份验证已启用,则创建一个通过寄存器和内存产生的依赖关系,从 Xn 的寄存器读取效果到 Xd 的寄存器写入效果。
译者注: PACDA(Pointer Authentication Code for Data address, using key A)是使用 A 密钥为数据地址生成指针认证码的指令。
RJMNSC 如果 FEAT_PAuth 已实现,则 PACDB Xd,Xn 指令的执行会创建:
- 一个通过寄存器和内存产生的依赖关系,从 Xd 的寄存器读取效果到 Xd 的寄存器写入效果。
- 如果使用 APDBKey_EL1 密钥的身份验证已启用,则创建一个通过寄存器和内存产生的依赖关系,从 Xn 的寄存器读取效果到 Xd 的寄存器写入效果。
译者注: PACDB(Pointer Authentication Code for Data address, using key B)是使用 B 密钥为数据地址生成指针认证码的指令。
RXYRJT 如果 FEAT_PAuth 已实现,则 AUTDA Xd,Xn 指令的执行会创建:
- 如果使用 APDAKey_EL1 密钥的身份验证已启用,则创建一个通过寄存器和内存产生的选择依赖(Pick dependency),从 Xn 的寄存器读取效果到 Xd 的寄存器写入效果。
- 一个通过寄存器和内存产生的依赖关系,从 Xd 的寄存器读取效果到 Xd 的寄存器写入效果。
译者注: AUTDA(AUThentication Data address, using key A)是使用 A 密钥验证数据地址的指令。Pick dependency(选择依赖)是一种特殊类型的依赖关系,当依赖值的选择取决于数据值本身时形成。
RSPBZX 如果 FEAT_PAuth 已实现,则 AUTDB Xd,Xn 指令的执行会创建:
- 如果使用 APDBKey_EL1 密钥的身份验证已启用,则创建一个通过寄存器和内存产生的选择依赖(Pick dependency),从 Xn 的寄存器读取效果到 Xd 的寄存器写入效果。
- 一个通过寄存器和内存产生的依赖关系,从 Xd 的寄存器读取效果到 Xd 的寄存器写入效果。
译者注: AUTDB(AUThentication Data address, using key B)是使用 B 密钥验证数据地址的指令。
B2.4.3 有限排序区域(Limited ordering regions)
FEAT_LOR 引入了有限排序区域(LORegions),它允许大型系统执行特殊的加载获取(load-acquire)和存储释放(store-release)指令,这些指令在 PA(物理地址)映射的某个区域内,为一组观察者所观察到的内存访问之间提供排序。
LORegions 在非安全(Non-secure)物理地址空间中定义。LORegions 不能在安全(Secure)、领域(Realm)或根(Root)物理地址空间中定义。
该特性仅在 AArch64 状态下受支持。
B2.4.3.1 LORegions 的规范(Specification of the LORegions)
LORegions 使用一组 LORegion 描述符(LORegion descriptor)在非安全物理内存映射中定义。LORegion 描述符的数量是实现定义(IMPLEMENTATION DEFINED)的,可以通过读取 LORID_EL1 寄存器来发现。
每个 LORegion 描述符包括:
- 以下值的元组:
- 起始地址(Start Address)。
- 结束地址(End Address)。
- LORegion 编号(LORegion Number)。
- 有效位(Valid bit),指示该 LORegion 描述符是否有效。
如果物理地址 PA 位于起始地址和结束地址之间(含两端),则该内存位置位于该 LORegion 编号标识的 LORegion 之内。起始地址必须定义为与 64KB 对齐,结束地址必须定义为某个 64KB 内存块的最高字节。
允许将多个具有不重叠地址范围的 LORegion 描述符配置为具有相同的 LORegion 编号。
LORegion 描述符通过系统寄存器空间中的 LORSA_EL1、LOREA_EL1、LORN_EL1 和 LORC_EL1 寄存器进行编程。这些寄存器仅描述非安全内存映射中的内存地址。如果在 SCR_EL3.NS == 0 时访问这些寄存器,则访问结果是未定义(UNDEFINED)的。
译者注: SCR_EL3.NS 是安全配置寄存器中的非安全位。当 NS==0 时表示处于安全状态,此时访问这些描述非安全内存映射的寄存器会导致 UNDEFINED 异常。
如果 LoadLOAcquire 或 StoreLORelease 未与任何 LORegion 匹配,则:
- LoadLOAcquire 将表现为加载获取(Load-Acquire),并且相对于所有访问(无论其 LORegion 如何)都以相同方式排序。
- StoreLORelease 将表现为存储释放(Store-Release),并且相对于所有访问(无论其 LORegion 如何)都以相同方式排序。
注:
如果没有实现任何 LORegions,则 LoadLOAcquire 和 StoreLORelease 将因此表现为 Load-Acquire 和 Store-Release。
B2.4.4 SVE 内存排序放宽(SVE memory ordering relaxations)
ICTNGV Arm 内存模型对于 SVE 加载和存储指令生成的读取和写入是**放宽(relaxed)**的。
译者注: SVE(Scalable Vector Extension)是 ARM 的可扩展向量扩展,支持可变长度向量操作。
RQLJPC 当 SVE 向量加载指令生成的两次读取之间存在地址依赖(address dependency)时,该依赖不对**依赖排序在前(dependency-ordered-before)**关系产生贡献。
RYMBMZ 当一对读取访问同一位置,并且其中至少一次读取由 SVE 加载指令生成时,对于给定的观察者,**冲突排序在前(hazard-ordered-before)**关系不适用于这对读取。
译者注: hazard-ordered-before 是 ARM 内存模型中的一种排序关系,用于处理同一观察者因存储缓冲区或其他原因导致的对同一位置的读写冲突排序。
RCJHWV 当单条 SVE 向量存储指令生成对同一位置的多次写入时,该指令确保这些写入在该位置的一致性顺序中按向量元素编号递增的顺序出现。对于同一 SVE 存储指令生成的存储器效果,不施加其他排序限制。
RLVXTJ 如果单条 SVE 加载指令生成多次读取,则不同元素和寄存器的读取出现的顺序不由架构定义。
RVMDYZ 如果两个读取内存(Read Memory)之间存在地址依赖,并且第二个读取由 SVE 非时态向量加载指令生成,则在没有任何其他屏障机制来实现排序的情况下,所访问内存地址的共享域内的其他观察者可以以任意顺序观察到这些内存访问。
ICCWGN 对于任何生成多次单拷贝原子访问(single-copy atomic accesses)到普通(Normal)或设备(Device)内存的 SVE 加载或存储指令,PE 之外的内存系统不需要能够识别单拷贝原子内存元素的访问大小。
译者注: 单拷贝原子访问(single-copy atomic access)是指对单个内存位置的访问,在硬件上以原子方式执行,不会被其他观察者中断或撕裂。
B2.4.5 流式 SVE 模式内存排序放宽(Streaming SVE mode memory ordering relaxations)
RHBBTV 如果一对内存读取访问同一位置,并且其中至少一次读取由 Advanced SIMD&FP 加载指令生成,则当 PE 处于流式 SVE 模式(Streaming SVE mode)且 FEAT_SME_FA64 未实现或在当前异常级别未启用时,对于给定的观察者,**冲突排序在前(hazard-ordered-before)**关系不适用于这对读取。
另请参见:
- 流式 SVE 模式(Streaming SVE mode)。
译者注: Streaming SVE mode 是 FEAT_SME(Scalable Matrix Extension)引入的一种模式,PE 在这种模式下执行流式 SVE 指令。FEAT_SME_FA64 特性允许在流式 SVE 模式下执行所有的 Advanced SIMD 和浮点指令。
B2.4.6 GCS 的排序规则(Ordering rules for GCS)
IQNKNL 如果 FEAT_GCS 已实现,参见**受保护的控制栈数据访问(Guarded Control Stack data accesses)**以了解相关的排序规则。
译者注: GCS(Guarded Control Stack)是 ARMv9 中引入的硬件安全特性,用于保护返回地址和控制流完整性,防止面向返回编程(ROP)攻击。
B2.5 推测执行影响的限制(Restrictions on the effects of speculation)
允许的推测执行下一PC(permitted-speculative-next-PC) 是以下之一:
- 对于既不是无条件分支(立即数)也不是异常生成指令的任何指令,其PC加四。
- 对于任何指令,一个异常向量。
- 对于直接分支,PC加上操作码立即数字段中包含的偏移量。
- 对于间接分支,任何地址。
允许的推测执行指令(permitted-speculatively-executed-instruction) 是对一个允许的推测执行下一PC(permitted-speculative-next-PC)上的指令进行的推测执行,其中该PC是由以下之一生成的:
- 一条架构执行的指令(architecturally executed instruction)。
- 一条允许的推测执行指令(permitted-speculatively-executed-instruction)。
Arm架构对推测执行的影响施加了某些限制。这些限制包括:
- 在作为上下文同步事件(Context Synchronization event)的异常返回之后,使用特定VA从某位置进行的每次加载,不会推测性地读取一致性顺序(coherence order)中早于该异常退出前使用相同VA对该位置进行的最新存储所生成的条目。
- 在作为上下文同步事件(Context Synchronization event)的异常进入之后,使用特定VA从某位置进行的每次加载,不会推测性地读取一致性顺序(coherence order)中早于该异常进入前使用相同VA对该位置进行的最新存储所生成的条目。
- 在作为上下文同步事件(Context Synchronization event)的异常进入之前,使用特定VA从某位置进行的任何加载,不会推测性地读取异常进入后使用相同VA对该位置进行的存储中的数据。
- 在作为上下文同步事件(Context Synchronization event)的异常返回之前,使用特定VA从某位置进行的任何加载,不会推测性地读取异常退出后使用相同VA对该位置进行的存储中的数据。
- 当数据在存在转换故障(Translation fault)的情况下被推测加载时,该数据不能用于形成地址、生成条件码(condition codes)或生成SVE谓词值(SVE predicate values)供推测序列中的其他指令使用。
- 在硬件定义的上下文(context2)中运行的指令(I2)所产生的推测性显式内存读取效应(speculative Explicit Memory Read Effect),不会从在不同硬件定义的上下文(context1)中运行的指令(I1)所产生的推测性显式内存写入效应(speculative Explicit Memory Write Effect)中推测性地读取数据,如果I1产生的是MMU故障效应(MMU fault Effect)而非显式内存写入效应(Explicit Memory Write Effect)。
- 当数据在存在GPC故障(GPC fault)的情况下被推测加载时,该数据不能用于形成地址、生成条件码(condition codes)或生成SVE谓词值(SVE predicate values)供推测序列中的其他指令使用,并且推测序列中任何其他指令的执行时序不能是被推测加载的数据的函数。
- 当启用阶段2转换(stage 2 translation)且阶段1转换表条目在存在GPC故障(GPC fault)的情况下被推测加载时,该条目的输出地址或下一级表地址不能用于形成地址供转换表遍历(translation table walk)中的其他获取操作使用。
- 颗粒保护检查(Granule protection checks)适用于推测性指令获取和推测执行。任何在存在GPC故障(GPC fault)情况下被推测获取的指令:
- 不得因指令的推测执行而导致任何架构状态或微架构状态的更新,其中该状态的更新依赖于指令的内容。
- 不得存储在不受DC PAPA操作影响的缓存中。
- 如果GPCCR_EL3.GPCP == 0,则对于正在进行颗粒保护检查但尚未架构性解析(architecturally resolved)的地址,来自该地址所访问的转换表遍历的数据,在颗粒保护检查通过之前,不能用于形成后续读取访问的地址或生成综合症信息(syndrome information)。
注:
允许对颗粒保护检查尚未架构性解析的位置进行读取访问,意味着GPT无法保护非幂等(non-idempotent)位置免受这些推测性读取操作的影响。
- 当数据从某个位置被推测加载,而该位置对于正在执行推测的转换机制没有有效转换(valid translation)时,该数据不能用于形成地址、生成条件码(condition codes)或生成SVE谓词值(SVE predicate values)供推测序列中的其他指令使用。
- 当数据作为TLBI + DSB + ERET之后使用已被TLBI失效的转换进行的推测访问的结果而被加载时,该数据不能用于形成地址、生成条件码(condition codes)或生成SVE谓词值(SVE predicate values)供推测序列中的其他指令使用。推测序列中任何其他指令的执行时序不能是被加载的数据的函数。
- 对系统寄存器(System registers)的更改不得以可能影响推测性内存访问的方式推测性地发生,而该推测性内存访问可能导致微架构状态的改变。
- 对特殊目的寄存器(Special-purpose registers)的更改可以推测性地发生。
- 对设备内存(Device memory)的访问受到许多关于推测影响的限制。参见”设备内存(Device memory)”。
- 禁止执行控制(Execute-never controls)适用于推测性指令获取。参见”对指令执行权限和指令获取限制的影响(Effects on instruction execution permissions and restrictions on instruction fetch)”。
- 当向内存写入新指令时,不要求使用SB指令(推测屏障指令)来防止旧代码的推测执行。参见”指令缓存维护指令(Instruction cache maintenance instructions)”。
- 对于所有内存类型,禁止对其他观察者可见的写入推测(write speculation)。
- 加载操作不会推测性地读取程序顺序(program order)中出现在该加载之后的任何存储中的数据。
- 从Armv9.4开始,不是允许的推测执行指令(permitted-speculatively-executed-instruction)的指令(I1),不得推测性地执行任何除获取、解码或执行因获取和解码而产生的副作用之外的功能,这些功能会改变系统的微架构状态,以至于某些其他架构执行的代码(code2)能够确定任何架构状态——除非是I1作为获取和解码的一部分所访问的架构状态——而这些架构状态在I1未推测执行的情况下是无法确定的。
当一个指向位置(A1)的架构或推测性显式内存写入效应(E1)被正确同步,以至于后续从A1进行的架构或推测性指令获取(I1)需要观察到E1时,从I1生成的允许的推测执行下一PC(permitted-speculative-next-PC)允许从E1对A1的修改之前或之后的操作码生成。
注:
禁止使用存在故障时推测加载的数据来形成地址、条件码或SVE谓词值,并不禁止将来自此类位置的值预测数据用于这些目的,只要该数据值预测的训练来自使用该预测的硬件定义的上下文。其结果是,值预测的训练不能基于在存在转换或权限故障(Translation or Permission fault)的情况下推测加载的数据。
B2.5.1 AArch64推测性存储绕过安全(AArch64 Speculative Store Bypass Safe,FEAT_SSBS)
当实现了FEAT_SSBS时,PSTATE.SSBS是一个可由软件设置的控制位,用于指示是否允许硬件以可能被推测利用(potentially speculatively exploitable)的方式使用寄存器中的推测值,该值是通过使用加载指令从内存加载的,该加载指令推测性地读取了被加载的位置,其中被推测读取的条目在一致性顺序(coherence order)中早于使用与该加载指令相同的虚拟地址对该位置进行的最新存储所生成的条目。
寄存器中的推测值如果用于形成地址、生成条件码、生成SVE谓词值供推测序列中的其他指令使用,或者推测序列中任何其他指令的执行时序是被推测加载的数据的函数,则该推测值被视为以可能被推测利用的方式被使用。
当PSTATE.SSBS的值为0时,如果加载寄存器的推测性读取在一致性顺序中早于使用与该加载指令相同的虚拟地址对该位置进行的最新存储所生成的条目,则不允许硬件以可能被推测利用的方式使用推测性寄存器值。
译者注: 将PSTATE.SSBS设置为0会禁用推测性存储绕过优化,从而防止某些侧信道攻击(如Spectre v4),但会带来性能损失。
由于性能原因,不推荐将PSTATE.SSBS设置为0。
当PSTATE.SSBS的值为1时,如果加载寄存器的推测性读取在一致性顺序中早于使用与该加载指令相同的虚拟地址对该位置进行的最新存储所生成的条目,则允许硬件以可能被推测利用的方式使用推测性寄存器值。
注:
- 如果允许推测执行,则缓存时序侧信道(cache timing side channels)可能导致通过读取已从内存推测加载到寄存器的地址值来推导出地址。
- 在引入FEAT_SSBS之前,控制位SPSR_ELx.SSBS为RES0,因此未考虑FEAT_SSBS而编写的软件预计会将其编程为0。这意味着PSTATE.SSBS不会被置位,因此如果后续推测性内存访问有可能创建缓存时序侧信道,PE将不允许对未完成的内存消歧问题使用推测加载进行任何后续推测性内存访问。
B2.5.2 推测执行利用性控制的定义(Definition of exploitative control of speculative execution)
某些代码(code1)的执行可以利用性控制(exploitatively control) 其他代码(code2)的推测执行,如果以下所有条件都满足:
- code1的行为能够以非难以确定(not hard-to-determine)的方式影响多比特值的预测,而这些预测决定了code2的推测执行,从而引起PE微架构状态的不可逆改变(irreversible change),该改变指示了code2执行上下文可访问的某些架构状态。
- code1在确定该微架构状态不可逆改变所指示的架构状态的选择方面具有控制权。
- PE微架构状态的不可逆改变可以由code2执行上下文之外的代码执行来测量,从而允许以非难以确定(not hard-to-determine)的方式恢复该架构状态。
注:
一个上下文驱逐另一个上下文的条目不被视为利用性控制,只要驱逐不会导致可能被利用性控制的其他形式的预测。
B2.5.3 推测执行预测性泄漏的定义(Definition of predictive leakage to speculative execution)
某些代码(code1)的执行可以预测性地泄漏(predictively leak) 给其他代码(code2),如果以下所有条件都满足:
- code1的执行以非难以确定(not hard-to-determine)的方式影响实现的预测性微架构结构——这些结构预测多比特值而非二元选择——使其行为方式指示了code1执行上下文可访问的某些架构状态。
- 实现的预测性微架构结构影响code2推测执行的时序,从而使code2能够以非难以确定(not hard-to-determine)的方式恢复该架构状态。
- Code1和code2并非协作使用前两个要点中的机制进行通信。
注:
防止影响和状态恢复”非难以确定”的机制由实现自行决定。示例可包括预测资源的完全分离,或使用加密或伪随机机制隔离每个上下文的预测。
一个上下文(code1)驱逐与另一个上下文(code2)相关联的预测性微架构结构中的条目,如果这使得code2能够从code1恢复某些架构状态,则被视为预测性泄漏。
B2.5.4 Armv8.5引入的推测执行影响的限制(Restrictions on the effects of speculation from Armv8.5)
注:
如果改变了SCR_EL3.EEL2,为了从安全EL1和安全EL0条目中移除所有VMID标记,应由软件使每个预测资源失效:
- 针对所有ASID和VMID值的安全EL0。
- 针对所有VMID值的安全EL1。
如下所述,一些额外的架构特性引入了对推测执行的进一步限制。
FEAT_CSV3 引入了以下限制:
- 在推测执行下尝试访问数据,而根据PE的当前状态该数据不可访问时,该尝试不得以允许通过架构执行的代码以测量代码时序等方式恢复不可访问数据值的方式改变架构或微架构状态。此限制适用于以下任何导致数据不可访问的情况:
- 从存在权限故障(Permission fault)或域故障(Domain fault)的位置读取。
- 直接从不可架构性读取的系统寄存器读取。
- 从由于更高特权异常级别配置的陷阱而不可访问的SIMD&FP寄存器、SVE寄存器或SME寄存器读取。
- 间接读取包含指针认证密钥(Pointer Authentication Key)的系统寄存器,而相应的指针认证指令被禁用。
注:
PE的当前状态定义为硬件尝试访问数据时的EL、所有特殊目的寄存器的值和所有系统寄存器的值,这可能在推测执行路径上。如果在推测执行路径上,硬件必须遵守在推测路径上发生的PE状态的任何更改,遵守与非推测路径上执行时相同的规则。请注意,推测路径上的指令序列可能与在非推测路径上发生的指令序列不同,因为硬件控制流预测可能导致两个序列不同。
注:
以下是使用不可访问数据可能导致恢复不可访问数据值的一些示例列表:
- 用于形成地址、生成条件码或生成SVE谓词值供推测序列中使用。
- 用于形成推测序列中比较并分支(compare-and-branch)、测试并分支(test-and-branch)或比较并交换(compare-and-swap)指令的比较所使用的寄存器值。注意,这是为了涵盖不使用条件码来确定其结果的条件指令。
- 通过预测机制,如缓存预取(Cache Prefetch)或数据值预测(Data Value predictions)。
- 作为推测序列中某条指令的输入,而该指令的执行时序取决于数据值。
注:
允许加载或寄存器读取产生零值,并由推测序列中比该加载更新的指令消费,即使零值与非零值相比导致不同的执行时序。
注:
由于推测执行的影响在架构上不可见,此限制要求任何推测执行的影响不得产生侧信道(side channels),将内存位置、系统寄存器或特殊目的寄存器的值泄漏到原本无法确定这些值的特权级别。
- 作为带有NoTagAccess故障(NoTagAccess fault)的标签检查访问(Tag checked access)或对未标签内存(Untagged memory)的访问的结果,在推测执行下加载的分配标签(Allocation tags)的值不得影响导致标签检查访问的指令或推测序列中其他指令的执行。
- 对系统寄存器(System registers)的更改不得以可能影响推测性内存访问的方式推测性地发生,而该推测性内存访问可能导致微架构状态的改变。
注:
对特殊目的寄存器(Special-purpose registers)的更改可以推测性地发生。
FEAT_CSV2、FEAT_CSV2_1p1、FEAT_CSV2_1p2、FEAT_CSV2_2和FEAT_CSV2_3 引入了一系列额外的限制。
如果实现了FEAT_CSV2:
- 在一个硬件定义的上下文(context1)中运行的代码,不能因以下任何资源的行为,利用性控制(exploitatively control)或预测性泄漏(predictively leak)给在另一个硬件定义的上下文(context2)中的代码的推测执行:
- 基于context1中使用的分支目标的分支目标预测(Branch target prediction)。
- 这适用于直接和间接分支,包括返回指令,但不包括条件分支方向的预测。
- 基于context1中使用的分支类型的分支类型预测(Branch type prediction),当硬件预测给定类型的分支是另一种类型的分支,并且该分支类型被用于利用性控制context2内间接分支的目标预测时。分支类型用于区分:
- 非分支、直接分支、间接分支以及分支并链接(branch and link,或调用)。
- 基于context1中执行的数据值的数据值预测(Data Value predictions)。
- 基于context1中使用的分支目标的分支目标预测(Branch target prediction)。
注:
来自context1的PSTATE.{N, Z, C, V}值不被视为用于此目的的数据值。
- 基于context1中执行的结果生成的、基于虚拟地址的缓存预取预测(Cache prefetch predictions),这些预测基于或导致对内存中数据值的解引用。
- 基于context1中使用的地址的地址预测(Address predictions)。
- 这包括任何形式的内存消歧预测(memory disambiguation prediction)或基于部分地址匹配的数据转发。
- 任何其他预测机制,而非分支预测、数据值预测、缓存预取预测或地址预测。
在此定义中,硬件定义的上下文由以下因素决定:
- 异常级别(Exception level)。
- 安全状态(Security state)。
- 当在EL1执行时,如果EL2在当前安全状态下已实现并启用,则还包括VMID。
- 当在EL0执行时,EL1&0或EL2&0转换机制中哪一个正在使用。
- 当在EL0执行且使用EL1&0转换机制时,地址空间标识符(ASID),以及如果EL2在当前安全状态下已实现并启用,则还包括VMID。
- 当在EL0执行且使用EL2&0转换机制时,ASID。
如果实现了FEAT_CSV2_2,则SCXTNUM_ELx也是硬件定义的上下文的一部分。
对于非特权内存访问指令生成的非特权访问,与非特权访问的数据地址和数据值相关联的硬件定义的上下文,被确定为如同该访问是由EL0执行的指令生成的。
如果实现了FEAT_CSV2_1p1或FEAT_CSV2_3,则在一个硬件定义的上下文(context1)中运行的代码不能因基于context1中使用的分支历史(branch history)的任何预测机制的行为,利用性控制或预测性泄漏给在另一个硬件定义的上下文(context2)中的代码的推测执行。
如果实现了FEAT_CSV2_1p1,则从一个指令地址训练的分支或数据值不能利用性控制或预测性泄漏给来自不同地址的代码的推测执行。
如果实现了FEAT_CSV2_1p2,则SCXTNUM_ELx寄存器已实现,但不是硬件定义的上下文的一部分。
B2.5.5 Armv9.5引入的推测执行影响的限制(Restrictions on the effects of speculation from Armv9.5)
如果实现了FEAT_BTI:
- 在推测执行下预测或执行进入受保护页(Guarded Page)的分支,如果其落在非预期的BTI指令上,则同样会被阻止对这些指令进行推测执行。
B2.5.6 分支历史(Branch history)
如果未实现FEAT_CLRBHB,则架构不为AArch64状态定义任何分支历史维护指令。
当实现了FEAT_CLRBHB时,CLRBHB指令可用。当执行CLRBHB指令时,当前上下文的分支历史被清除,其程度为:在CLRBHB指令之前创建的分支历史信息不能被CLRBHB指令之前的代码用于利用性控制在程序顺序中出现在该指令之后的当前上下文中的任何代码的执行。
当实现了FEAT_ECBHB时,在一个上下文中、在异常进入更高异常级别(使用AArch64)之前创建的分支历史信息,不能被该异常进入之前的代码用于利用性控制在异常进入之后不同上下文中的任何代码的执行。
注:
FEAT_CLRBHB和FEAT_ECBHB限制分支历史的使用以防止利用性控制。这些限制仅适用于受FEAT_CSV2保护的预测资源。
B2.5.7 执行、数据预测和预取限制系统指令(Execution, data prediction and prefetching restriction System instructions)
当单独实现了FEAT_SPECRES或与FEAT_SPECRES2一同实现时,A64系统指令中用于预测限制的系统指令(参见”用于预测限制的A64系统指令(A64 System instructions for prediction restriction)”)可防止基于特定执行上下文(CTX)中先前执行收集的信息的预测,影响该CTX内后续的推测执行,其程度为使推测执行可通过侧信道(side-channels)被观察到。
特定CTX使用的预测限制系统指令适用于:
- 所有预测执行地址的控制流预测资源(control flow prediction resources)。
- 数据值预测(Data value prediction)。
- 缓存分配预测(Cache allocation prediction)。
对于这些系统指令,CTX由以下因素定义:
- 安全状态(Security state)。
- 异常级别(Exception level)。
- 当在EL1执行时,如果EL2在当前安全状态下已实现并启用,则还包括VMID。
- 当在EL0执行时,EL1&0或EL2&0转换机制中哪一个正在使用。
- 当在EL0执行且使用EL1&0转换机制时,ASID,以及如果EL2在当前安全状态下已实现并启用,则还包括VMID。
- 当在EL0执行且使用EL2&0转换机制时,ASID。
注:
- 数据值预测适用于所有使用某种形式的训练来推测数据值作为执行一部分的预测资源。
- 缓存分配适用于执行PE使用的所有指令缓存和数据缓存,以及适用于所提供的上下文的TLB预取硬件。
上下文信息作为寄存器参数传递,并受到如下限制:
- 在EL0执行系统指令仅适用于当前硬件定义的上下文。
- 在EL1执行系统指令仅适用于当前VMID和安全状态,不适用于EL2或EL3。
- 在EL2执行系统指令仅适用于当前安全状态,不适用于EL3。
如果系统指令指定应用于未实现的安全状态和异常级别的组合,或应用于高于执行该系统指令的异常级别的异常级别,则该系统指令被视为NOP(空操作)。
当系统指令完成并同步后,受影响的上下文中受限类型的预测不会受到该系统指令之前程序执行的影响,其方式可通过使用任何侧信道观察到。
注:
- 预测限制系统指令不需要使预测结构失效,只要实现满足所描述的完成行为即可。
- 预测限制系统指令允许使比所提供的执行上下文定义的更多的预测信息失效。
这些系统指令保证在覆盖同一PE上执行原始指令的读写行为的DSB之后完成。需要后续的上下文同步事件(Context synchronization event)以确保指令完成的效果与当前执行同步。
在AArch64状态下,EL0对系统指令的访问由以下因素控制:
- 当HCR_EL2.{E2H, TGE}的有效值不是{1, 1}时,由SCTLR_EL1.EnRCTX控制。
- 当HCR_EL2.{E2H, TGE}的有效值是{1, 1}时,由SCTLR_EL2.EnRCTX控制。
注:
如果改变了SCR_EL3.EEL2,为了从安全EL1和安全EL0条目中移除所有VMID标记,每个预测资源应被失效:
- 针对所有ASID和VMID值的安全EL0。
- 针对所有VMID值的安全EL1。
B2.6 内存屏障(Memory barriers)
B2.6 内存屏障
内存屏障是一个通用术语,指一条或多条指令序列,由PE强制在退役(retiring)加载/存储指令时产生同步事件。Arm架构定义的内存屏障提供了一系列功能,包括:
- 加载/存储指令的排序(Ordering)。
- 加载/存储指令的完成(Completion)。
- 上下文同步(Context synchronization)。
以下小节描述了Arm内存屏障指令:
- 指令同步屏障(Instruction Synchronization Barrier)。
- 数据内存屏障(Data Memory Barrier)。
- 推测屏障(Speculation Barrier)。
- 推测数据消费屏障(Consumption of Speculative Data Barrier)。
- 推测存储绕过屏障(Speculative Store Bypass Barrier)。
- 性能分析同步屏障(Profiling Synchronization Barrier)。
- 物理推测存储绕过屏障(Physical Speculative Store Bypass Barrier)。
- 跟踪同步屏障(Trace Synchronization Barrier)。
- 数据同步屏障(Data Synchronization Barrier)。
- 加载-获取(Load-Acquire)、加载-获取PC(Load-AcquirePC)和存储-释放(Store-Release)。
- LoadLOAcquire、StoreLORelease。
- 保护控制栈屏障(Guarded Control Stack Barrier, GCSB)。
注意
根据所需的同步类型,程序可以单独使用内存屏障,也可以将内存屏障与高速缓存维护(cache maintenance)和内存管理指令结合使用,这些指令通常仅在软件执行于EL1或更高异常级别时可用。
DMB和DSB指令影响由PE执行的加载/存储指令以及数据或统一高速缓存维护指令对内存系统产生的读写操作。
译者注:DMB、DSB、ISB三大屏障指令的区别:
- DMB(数据内存屏障):确保屏障前后的内存访问的相对顺序,但不保证这些内存访问已经完成。DMB关注的是排序(ordering),而非完成(completion)。适用于需要保证内存访问顺序但无需等待完成的场景。
- DSB(数据同步屏障):确保屏障之前的内存访问在DSB指令完成之前已经完成(completed)。DSB比DMB更强,包含DMB的所有排序功能,并额外要求等待所有指定的内存访问实际完成。适用于需要等待内存访问真正完成的场景(如TLB维护后)。
- ISB(指令同步屏障):确保ISB之后的所有指令都从缓存或内存中重新获取。ISB用于刷新处理器流水线,使前面上下文变更操作(如系统寄存器修改、Cache/TLB维护)的效果对后面指令可见。
简言之:DMB只管顺序不管完成;DSB既管顺序也管完成;ISB用于指令获取同步。
B2.6.1 指令同步屏障(Instruction Synchronization Barrier)
ISB指令确保在程序顺序中位于ISB指令之后的所有指令,都在ISB指令完成之后从缓存或内存中获取。使用ISB可以确保在ISB之前执行的上下文变更操作(context-changing operations)的效果,对ISB之后获取的指令可见。需要插入ISB指令以确保操作效果对ISB之后获取的指令可见的上下文变更操作示例包括:
- 已完成的缓存和TLB维护指令。
- 对系统寄存器的修改。
在程序顺序中出现在ISB指令之后的任何上下文变更操作,只有在ISB执行之后才会生效。
ISB操作的伪代码函数为 InstructionSynchronizationBarrier()。
另请参见内存屏障(Memory barriers)。
B2.6.2 数据内存屏障(Data Memory Barrier)
DMB指令是一条内存屏障指令,用于确保屏障之前的内存访问与屏障之后的内存访问之间的相对顺序。DMB指令不确保其所保证相对顺序的任何内存访问已经完成。
DMB指令的完整定义由形式化并发模型(formal concurrency model)定义的排序需求(Ordering requirements)正式涵盖,此处对DMB指令的介绍无意与该部分内容相矛盾。
DMB指令的基本原理是在DMB指令参数指定的、受DMB影响的内存访问之间引入顺序。DMB指令确保:执行DMB指令的PE在程序顺序中位于DMB之前的所有受影响的内存访问,以及来自其他PE的、在DMB指令执行之前已由本PE以DMB选项所要求的方式观察到的内存访问,每个PE都以DMB选项所要求的方式观察到这些访问后,才能观察到在程序顺序中位于DMB之后的任何受影响的内存访问。
使用DMB指令在指令的内存效果(Memory effects)之间创建顺序,如”屏障有序前”(Barrier-ordered-before)定义所述。
DMB指令仅影响内存访问以及数据缓存和统一缓存维护指令的操作,参见A64缓存维护指令。它不影响PE上执行的任何其他指令的排序。
DMB操作的伪代码函数为 DataMemoryBarrier()。
B2.6.3 推测屏障(Speculation Barrier)
SB指令是一条内存屏障,用于阻止在屏障完成后、那些可能通过侧信道(side-channels)被观察到的指令的推测执行,直到屏障完成。
在屏障完成之前,任何在程序顺序中晚于屏障的指令都不能进行推测执行(如果这种推测可以通过侧信道被观察到,且是由控制流推测(control flow speculation)或数据值推测(data value speculation)导致的)。一个示例是向任何缓存结构中进行推测分配,如果该条目的分配可能指示内存或寄存器中存在的任何数据值。
- 不能进行到这种推测可以通过侧信道作为控制流推测或数据值推测的结果被观察到的程度。
- 可以在预测一条可能产生异常的指令不会产生异常时进行推测。
SB指令的推测执行不能由以下任何一种原因导致:
- 控制流推测。
- 数据值推测。
- 可以是预测一条可能产生异常的指令不会产生异常的结果。
当以下所有条件满足时,SB指令可以完成:
- 已知它不是推测性的,或者它仅仅是以下任一原因导致的推测:
- 推测一条可能产生异常的指令不会产生异常。
- 推测执行流中超过精确异步异常被获取的点之后的位置。
- 在程序顺序中出现在SB指令之前的所有指令生成的数据值在架构上已解析(architecturally resolved),因此不是推测性的。
注意
SB指令不影响使用预测资源来预测正在获取的指令流,前提是指令流的预测不受从程序顺序中SB指令之后出现的指令的推测执行的寄存器输出结果所影响。
B2.6.4 推测数据消费屏障(Consumption of Speculative Data Barrier)
CSDB指令是一条内存屏障指令,用于控制由数据值预测(data value prediction)引起的推测执行。
任何非分支指令,如果在程序顺序中出现在CSDB之后,都不能使用以下任何预测的结果进行推测执行(如果这些预测来自程序顺序中位于CSDB之前且尚未在架构上解析的指令):
- 任何指令的数据值预测。
- 任何指令的 PSTATE.{N, Z, C, V} 预测(但不包括出现在程序顺序中CSDB之前且尚未在架构上解析的条件分支指令的预测)。
- 任何SVE指令的SVE谓词状态(SVE predication state)预测。
注意
就CSDB的定义而言,PSTATE.{N, Z, C, V} 和 SVE谓词状态不被视为数据值。此定义允许:
- CSDB指令前后的控制流推测。
- CSDB指令之后的条件数据处理指令的推测执行,除非它们使用了程序顺序中位于CSDB指令之前的、尚未在架构上解析的指令的数据值、SVE谓词状态或 PSTATE.{N, Z, C, V} 预测的结果。
B2.6.5 推测存储绕过屏障(Speculative Store Bypass Barrier)
SSBB指令是一条内存屏障,用于防止在某些条件下推测性加载绕过对同一虚拟地址的较早存储。
推测存储绕过屏障的语义如下:
- 当对某个位置的加载在程序顺序中出现在SSBB指令之后时,该加载不会推测性地读取该位置的缓存一致性顺序(coherence order)中早于满足以下所有条件的最新存储所生成的条目的值:
- 该存储与加载针对同一位置。
- 该存储使用与加载相同的虚拟地址。
- 该存储在程序顺序中出现在SSBB指令之前。
B2.6.6 性能分析同步屏障(Profiling Synchronization Barrier)
PSB指令是一条屏障,用于确保当前PE的所有现有性能分析数据已经格式化,并且性能分析缓冲区地址已经转换,使得所有对性能分析缓冲区的写入已经发起。后续的DSB指令在性能分析缓冲区的写入完成时完成。
如果未实现统计性能分析扩展(Statistical Profiling Extension),该指令作为NOP执行。
B2.6.7 物理推测存储绕过屏障(Physical Speculative Store Bypass Barrier)
PSSBB指令是一条内存屏障,用于防止在某些条件下推测性加载绕过对同一物理地址的较早存储。
物理推测存储绕过屏障的语义如下:
- 当对某个位置的加载在程序顺序中出现在PSSBB指令之后时,该加载不会推测性地读取该位置的缓存一致性顺序(coherence order)中早于满足以下所有条件的最新存储所生成的条目的值:
- 该存储与加载针对同一位置。
- 该存储在程序顺序中出现在PSSBB指令之前。
注意
此屏障的效果适用于对同一位置的访问,即使它们使用不同的虚拟地址并从不同的异常级别进行访问。
B2.6.8 跟踪同步屏障(Trace Synchronization Barrier)
TSB指令是一条屏障指令,用于保持由跟踪操作(trace operations)引起的对系统寄存器的访问与对其他同一寄存器访问之间的相对顺序。
跟踪操作是指当实现了且启用了 FEAT_TRF 时,跟踪单元为某条指令生成跟踪的操作。
TSB指令不需要相对于其他指令按程序顺序执行。这包括相对于其他跟踪指令的重排序。需要一个或多个上下文同步事件(Context synchronization events)来确保TSB指令按必要的顺序执行。
如果在上下文同步事件和TSB操作之间生成了跟踪,这些跟踪操作可能与TSB操作重排序,因此可能不会被同步。
以下情况使用TSB操作进行同步:
- 对系统寄存器的直接写操作B,与跟踪指令A的跟踪操作对同一寄存器的间接读或间接写操作排序在后,如果满足以下所有条件:
- A在程序顺序中在上下文同步事件C之前执行。
- C在程序顺序中出现在TSB操作T之前。
- B在程序顺序中在T之后执行。
- 对系统寄存器的直接读操作B,与跟踪指令A的跟踪操作对同一寄存器的间接写操作排序在后,如果满足以下所有条件:
- A在程序顺序中在上下文同步事件C1之前执行。
- C1在程序顺序中出现在TSB操作T之前。
- T在程序顺序中在第二个上下文同步事件C2之前执行。
- B在程序顺序中在C2之后执行。
如果满足以下所有条件,则不需要TSB操作来确保对系统寄存器的直接写操作B排序在跟踪指令A的跟踪操作对同一寄存器的间接读或间接写之前:
- A在上下文同步事件C之后按程序顺序执行。
- B在C之前按程序顺序执行。
如果实现了 FEAT_TRBE,本节的要求会扩展。
参见同步与跟踪缓冲区单元(Synchronization and the Trace Buffer Unit)。
TSB指令的伪代码函数为 TraceSynchronizationBarrier()。
B2.6.9 数据同步屏障(Data Synchronization Barrier)
DSB指令是一条内存屏障,用于确保在DSB指令之前发生的内存访问在DSB指令完成之前已经完成。因此,它作为比DMB更强的屏障,DMB在特定选项下创建的所有排序,DSB在相同选项下也会生成。
执行DSB指令:
- 在EL2级别:确保由EL1&0转换机制(translation regime)的推测转换表遍历(Speculative translation table walks)所引起的任何内存访问已被观察到。
- 在EL3级别:确保由EL2、EL1&0或EL2&0转换机制的推测转换表遍历所引起的任何内存访问已被观察到。
更多信息,请参见上下文外转换机制(Out-of-context translation regimes)。
当对于所需共享性域(shareability domain)中的观察者集合,以下所有操作都完成时,由PE执行的DSB指令完成:
- 如果DSB所需的访问类型是读(reads),则需完成以下所有操作:
- 由程序顺序中位于DSB之前的指令生成的所有显式内存读效果(Explicit Memory Read Effects)。
- 如果实现了 FEAT_GCS,所有在程序顺序中出现在DSB之前的GCSB指令之前的GCS内存读效果。
- 如果实现了 FEAT_MTE2,由程序顺序中位于DSB之前的指令生成的所有隐式标签内存读效果(Implicit Tag Memory Read Effects)。
- 如果DSB所需的访问类型是写(writes),则需完成以下所有操作:
- 由程序顺序中位于DSB之前的指令生成的所有显式内存写效果(Explicit Memory Write Effects)。
- 如果实现了 FEAT_GCS,所有在程序顺序中出现在DSB之前的GCSB指令之前的GCS内存写效果。
- 如果DSB所需的访问类型是读写(reads and writes),则需完成以下所有操作:
- 由程序顺序中位于DSB之前的指令生成的所有显式内存效果(Explicit Memory Effects)。
- 由程序顺序中位于DSB之前的指令生成的所有隐式TTD内存效果(Implicit TTD Memory Effects)。
- 由程序顺序中位于DSB之前的指令生成的所有隐式指令内存读效果(Implicit Instruction Memory Read Effects)。
- 程序顺序中位于DSB之前的所有高速缓存维护指令。
- 如果实现了 FEAT_MTE2,由程序顺序中位于DSB之前的指令生成的所有隐式标签内存读效果。
- 如果实现了 FEAT_SPMU,由程序顺序中位于DSB之前的指令生成的对系统PMU寄存器的所有直接系统寄存器写效果(Direct System Register Write Effects)。
- 如果实现了 FEAT_SPE,程序顺序中位于DSB之前的所有PSB CSYNC指令。
- 如果实现了 FEAT_XS 且DSB具有 nXS 限定符,则需完成以下所有操作:
- 由带有 nXS 限定符的AArch64 TLB维护指令在程序顺序中位于DSB之前生成的所有TLBInXS维护操作。
- 如果 HCRX_EL2.FnXS 为1,由在EL1执行的带有 nXS 限定符的AArch32或AArch64 TLB维护指令在程序顺序中位于DSB之前生成的所有TLBInXS维护操作。
- 如果未实现 FEAT_XS 或DSB没有 nXS 限定符,则需完成以下所有操作:
- 由TLB维护指令在程序顺序中位于DSB之前生成的所有TLBI维护操作。
- 如果实现了 FEAT_HDBSS 且DSB在EL2或EL3执行,由程序顺序中位于DSB之前的指令生成的所有HDBSS内存写效果。
- 如果实现了 FEAT_TRBE,程序顺序中位于DSB之前的所有TSB CSYNC指令。
- 程序顺序中位于DSB之前的所有CFP RCTX、COSP RCTX、CPP RCTX、DVP RCTX指令。
- 如果实现了 FEAT_MTE_ASYNC,由程序顺序中位于DSB之前的指令生成的、对ELx可访问的标签故障状态寄存器(Tag Fault Status Register)的所有间接系统寄存器写效果。
- 如果实现了 FEAT_GCS,所有在程序顺序中出现在DSB之前的GCSB指令之前的GCS内存效果。
此外,在程序顺序中出现在DSB指令之后的任何指令,在DSB完成之前,不能改变系统的任何状态或执行其任何功能,以下情况除外:
- 从内存中获取和解码,或由获取或解码导致的架构或微架构状态的任何变化。
- 间接或直接读取以下任何资源,前提是读取这些资源不会导致架构状态的变化:
- 通用寄存器(General-purpose registers)
- SIMD&FP寄存器
- 栈指针寄存器(Stack Pointer)
- 程序计数器(Program Counter)
- 如果实现了 FEAT_SVE 或 FEAT_SME,SVE可扩展向量寄存器或SVE谓词寄存器
- 如果实现了 FEAT_SVE,首次故障寄存器(First Fault Register)
- 如果实现了 FEAT_SME,ZA存储
- 如果实现了 FEAT_SME2,ZT0寄存器
- 专用寄存器(Special-purpose registers)
- 除 CNTPCTSS_EL0 和 CNTVCTSS_EL0 之外的系统寄存器
- 如果未实现 FEAT_ETS2,转换(translating)生成显式内存效果(Explicit Memory Effects)的指令的任何虚拟地址。
如果实现了 FEAT_MTE_ASYNC,在带有LD限定符或不带LD和ST限定符的DSB指令完成时,由于在DSB之前的程序顺序中出现的指令所引起的标签检查故障(Tag Check Faults)而对 TFSR_ELx.TFy 或 TFSRE0_EL1.TFy 的所有更新都将完成。更多关于 FEAT_MTE_ASYNC 的信息,请参见内存标签扩展(Memory Tagging Extension)。
当实现了 FEAT_XS 且 HCRX_EL2.FnXS 为1时,在EL1或EL0执行的AArch64 DSB指令的行为与在EL1或EL0执行的带有 nXS 限定符的相应DSB指令相同。
在直接写操作之后排序的DSB指令,只有在所有观察者都观察到该直接写操作后才会完成。需要上下文同步事件来在直接写操作和DSB指令之间创建顺序。
如果实现了 FEAT_TRBE,本节的要求会扩展。请参见跟踪同步与内存屏障(Trace synchronization and memory barriers)。
DSB操作的伪代码函数为 DataSynchronizationBarrier()。
另请参见:
- 内存屏障(Memory barriers)。
- TLB维护指令的排序与完成(Ordering and completion of TLB maintenance instructions)。
B2.6.9.1 数据同步屏障操作的维护范围(Maintenance scope of the data synchronization barrier operations)
适用于读和写的DSB指令接受一个参数来指定其维护范围(maintenance scope)。维护范围指示此DSB所覆盖的TLB无效指令(TLBI)、TLB无效配对指令(TLBIP)和指令高速缓存维护(IC)指令的子集,针对以下之一:
- 外部共享域(Outer Shareable domain)。
- 内部共享域(Inner Shareable domain)。
- 非共享域(Non-shareable domain)。
当使用适用于读和写的DSB指令来确保TLB维护指令或指令高速缓存(IC)指令的完成时,以下所有规则适用:
- DSB NSH 足以确保应用于单个PE的TLB维护指令或IC指令的完成。
- DSB ISH 足以确保应用于同一内部共享域内PE的TLB维护指令或IC指令的完成。
- DSB OSH 足以确保应用于同一外部共享域内PE的TLB维护指令的完成。
译者注(DSB维护范围):
DSB的NSH/ISH/OSH参数指定了屏障的”可见性范围”:
- NSH(Non-Shareable,非共享):仅影响当前PE,用于单核场景下的TLB/IC维护完成确认。
- ISH(Inner Shareable,内部共享):影响同一内部共享域内的所有PE,用于多核但同簇(cluster)内的同步。
- OSH(Outer Shareable,外部共享):影响同一外部共享域内的所有PE,用于跨簇(多集群系统)的同步。
选择原则:范围越小,性能开销越低。单核操作使用NSH,多核同簇使用ISH,跨簇系统使用OSH。
B2.6.10 加载-获取(Load-Acquire)、加载-获取PC(Load-AcquirePC)和存储-释放(Store-Release)
Arm提供了一组具有获取语义(Acquire semantics)的加载指令和具有释放语义(Release semantics)的存储指令。这些指令支持释放一致性顺序一致性(Release Consistency sequentially consistent, RCsc)模型。此外,FEAT_LRCPC 提供了加载-获取PC(Load-AcquirePC)指令。加载-获取PC和存储-释放的组合可以用于支持较弱的释放一致性处理器一致性(Release Consistency processor consistent, RCpc)模型。
加载-获取和加载-获取PC指令的完整定义由形式化并发模型定义的排序需求正式涵盖。此处对加载-获取和加载-获取PC指令的介绍无意与该部分内容相矛盾。
加载-获取和加载-获取PC指令两者的基本原理都是在以下两者之间引入顺序:
- 由加载-获取或加载-获取PC指令生成的内存访问。
- 在程序顺序中出现在加载-获取或加载-获取PC指令之后的内存访问。
使得由加载-获取或加载-获取PC指令生成的内存访问在要求该PE一致性地观察该访问的范围内,被每个PE观察到的时刻,早于在程序顺序中出现在加载-获取或加载-获取PC指令之后的任何内存访问在被要求一致性地观察该访问的范围内被该PE观察到的时刻。
使用加载-获取或加载-获取PC指令在指令的内存效果之间创建顺序,如”屏障有序前”定义所述。
存储-释放指令的完整定义由形式化并发模型定义的排序需求正式涵盖,此处对存储-释放指令的介绍无意与该部分内容相矛盾。
存储-释放指令的基本原理是在以下两者之间引入顺序:
- 一组内存访问 RWx,由执行存储-释放指令的PE生成且在程序顺序中出现在存储-释放指令之前,以及来自不同PE的、在该PE执行存储-释放之前该PE被要求一致性地观察到的访问(在要求该PE观察的范围内)。
- 由存储-释放生成的内存访问(Wrel),使得所有内存访问 RWx 在每个PE被要求一致性地观察这些访问的范围内被每个PE观察到之后,Wrel 才在该PE被要求一致性地观察该访问的范围内被该PE观察到。
使用存储-释放指令在指令的内存效果之间创建顺序,如”屏障有序前”定义所述。
当加载-获取在程序顺序中出现在存储-释放之后时,存储-释放指令生成的内存访问在每个PE被要求一致性地观察该访问的范围内被该PE观察到的时刻,早于加载-获取指令生成的内存访问在该PE被要求一致性地观察该访问的范围内被该PE观察到的时刻。此外,对于对内存映射外设(Memory-mapped peripheral)的访问,使用加载-获取、加载-获取PC或存储-释放指令在访问该外设的指令的内存效果之间创建顺序,如”外设到达顺序”(Peripheral arrival order)定义所述。
加载-获取、加载-获取PC和存储-释放(加载-获取独占对和存储-释放独占对除外)仅访问单个数据元素。
加载-获取独占对(Load-Acquire Exclusive Pair)和存储-释放独占对(Store-Release Exclusive Pair)访问两个数据元素。
存储-释放独占(Store-Release Exclusive)指令仅在存储成功时具有释放语义。
注意
- 每个加载-获取独占和存储-释放独占指令本质上是等效的加载独占(Load-Exclusive)或存储独占(Store-Exclusive)指令的变体。所有使用限制和单拷贝原子性(single-copy atomicity)属性:
- 适用于加载独占指令的也同样适用于加载-获取独占指令。
- 适用于存储独占指令的也同样适用于存储-释放独占指令。
- 加载-获取、加载-获取PC和存储-释放指令可以消除使用显式DMB指令的需求。
B2.6.11 LoadLOAcquire、StoreLORelease
对于每个PE,非安全物理内存映射被划分为一组有限排序区域(LORegions),使用PE内部持有的表进行管理。非安全内存映射中的任何PA都可以是一个LORegion的成员。如果一个PA被分配给了多个LORegion,则实现可能会将其视为已分配给了少于指定数量的LORegion。如果一个PA不在非安全物理内存映射中,则该PA不能是任何LORegion的成员。更多信息,请参见有限排序区域(Limited ordering regions)。
FEAT_LOR 提供了一组具有获取语义的加载指令和具有释放语义的存储指令,这些指令相对于已定义的LORegions生效。加载-获取和存储-释放指令的新变体是 LoadLOAcquire 和 StoreLORelease。请参见 LoadLOAcquire/StoreLORelease。
对于所有内存类型,这些指令具有以下排序要求:
- LoadLOAcquire 与加载-获取具有相同的语义,不同之处在于受影响的内存访问位于与 LoadLOAcquire 指令生成的内存访问地址相同的 LORegion 内。参见加载-获取、加载-获取PC和存储-释放。
- StoreLORelease 与存储-释放具有相同的语义,不同之处在于受影响的内存访问位于与 StoreLORelease 指令生成的内存访问地址相同的 LORegion 内。参见加载-获取、加载-获取PC和存储-释放。
此外,对于对内存映射外设的访问:
- LoadLOAcquire 与加载-获取具有相同的语义,不同之处在于受影响的外设访问指令的内存效果位于与 LoadLOAcquire 指令生成的内存访问地址相同的 LORegion 内。参见加载-获取、加载-获取PC和存储-释放。
- StoreLORelease 与存储-释放具有相同的语义,不同之处在于受影响的外设访问指令的内存效果位于与 StoreLORelease 指令生成的内存访问地址相同的 LORegion 内。参见加载-获取、加载-获取PC和存储-释放。
注意
LoadLOAcquire/StoreLORelease 指令可以消除使用显式DMB指令的需求。
B2.6.12 保护控制栈屏障(Guarded Control Stack Barrier, GCSB)
GCSB指令是一条屏障指令,用于生成一个GCSB事件。GCSB事件在通用加载/存储访问与保护控制栈数据访问之间应用排序要求。更多信息,请参见保护控制栈数据访问行为(Guarded Control Stack data access behaviors)。
如果未实现 FEAT_GCS,该指令作为NOP执行。
B2.7 缓存和内存层次结构(Caches and memory hierarchy)
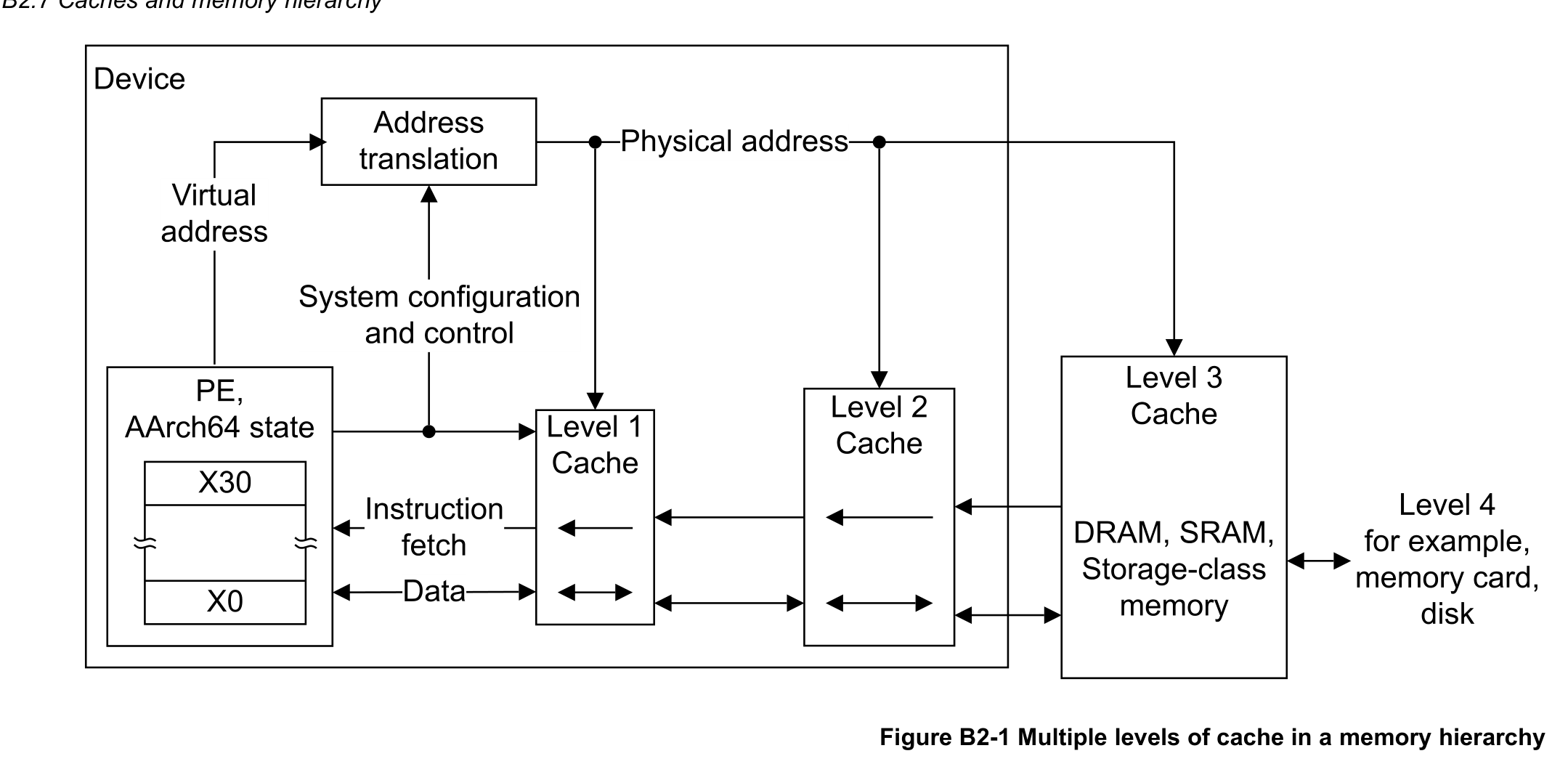
内存系统的实现在很大程度上依赖于微架构,因此内存系统的许多细节是由实现定义的(IMPLEMENTATION DEFINED)。Arm 架构定义了内存系统的应用程序级接口,包括包含多级缓存的层次化内存系统。本节描述该系统的应用程序级视图。它包含以下子节:
- 缓存简介。
- 内存层次结构。
- 应用程序级别访问与缓存相关的功能。
- 缓存对应用程序员的影响。
- 预取到缓存。
B2.7.1 缓存简介(Introduction to caches)
缓存是一块高速存储块,包含若干条目,每个条目由以下部分组成:
- 主存地址信息,通常称为标签(tag)。
- 相关联的数据。
缓存提高了内存访问的平均速度。缓存利用了两种局部性原理:
空间局部性(Spatial locality)
对一个位置的访问很可能会随后访问相邻位置。该原理的示例包括:
- 顺序指令执行。
- 访问数据结构。
时间局部性(Temporal locality)
对一个内存区域的访问很可能会在短时间内重复。该原理的示例是软件循环的执行。
为最小化存储的控制信息量,空间局部性特性将多个位置组合在同一个标签下。这个逻辑块通常称为缓存行(cache line)。当数据被加载到缓存中时,后续加载和存储的访问时间会缩短,从而带来整体性能的提升。访问已在缓存中的信息称为缓存命中(cache hit),其他访问称为缓存未命中(cache miss)。
通常情况下,缓存是自管理的,更新会自动发生。每当 PE 访问一个可缓存(cacheable)的内存位置时,都会检查缓存。如果访问是缓存命中,则在缓存中执行该访问。否则,访问将直接发往内存。通常,在进行此访问时,会分配一个缓存位置并将缓存行从内存中加载。Arm 架构允许不同的缓存拓扑和访问策略,前提是它们符合本手册中描述的内存一致性模型。
缓存会引入一些潜在问题,主要原因是:
- 内存访问可能发生在程序员预期之外的时间。
- 一个数据项可能保存在多个物理位置中。
B2.7.2 内存层次结构(Memory hierarchy)
通常,靠近 PE 的内存延迟非常低,但容量有限且实现成本高昂。随着距离 PE 变远,通常会实现更大的内存块,但这些内存具有更高的延迟。为优化整体性能,Armv8 内存系统可以在层次化内存系统中包含多级缓存,以利用这种大小与延迟之间的权衡。图 B2-1 展示了一个支持虚拟地址的 Armv8-A 系统中此类内存系统的示例。
(图 B2-1 内存层次结构中的多级缓存)
译者注: 图 B2-1 在原文中为示意图,展示了从 PE 出发,依次经过 Level 1 缓存(分离的指令缓存和数据缓存)、Level 2 缓存(统一缓存),直至主存的层次结构。
注意: 在本手册中,对于层次化内存系统,Level 1 指的是最靠近处理元素的级别,如图 B2-1 所示。
指令和数据可以保存在分离的缓存中,也可以保存在统一的缓存中。缓存层次结构可以有一个或多个级别的分离指令缓存和数据缓存,并带有一个或多个位于最靠近主存级别的统一缓存。可以使用以下概念性节点来定义缓存拓扑的内存一致性:统一点(Point of Unification, PoU)、一致点(Point of Coherency, PoC)、持久点(Point of Persistence, PoP) 和 深度持久点(Point of Deep Persistence, PoDP)。
译者注: PoU(Point of Unification)指系统中所有处理单元(PE)对指令和数据的观察达到一致的点;PoC(Point of Coherency)指系统中所有观察者(包括 DMA 等)对数据的观察达到一致的点;PoP(Point of Persistence)指数据到达持久化存储的点;PoDP(Point of Deep Persistence)指数据到达深度持久化存储的点。
更多信息,包括 PoU、PoC、PoP 和 PoDP 的定义,请参见 About cache maintenance in AArch64 state。
如果实现了 FEAT_MTE2,缓存维护指令的行为将被修改。更多信息,请参见 Allocation Tags。
B2.7.2.1 可缓存性和可共享性内存属性(The cacheability and shareability memory attributes)
可缓存性(Cacheability) 和 可共享性(Shareability) 是两种描述多处理系统中内存层次结构的属性:
可缓存性(Cacheability) 该属性定义内存位置是否允许被分配到缓存中。可缓存性为内部(Inner)和外部(Outer)可缓存性位置分别独立定义。
可共享性(Shareability) 该属性定义内存位置是否在系统中的不同代理之间共享。将内存位置标记为特定域的可共享,需要硬件确保该域中所有代理对该位置的视图是一致的。可共享性为内部(Inner)和外部(Outer)可共享性域分别独立定义。
关于可缓存性和可共享性的更多信息,请参见 Memory types and attributes。
B2.7.3 应用程序级别访问与缓存相关的功能(Application level access to functionality related to caches)
如 About the Application level programmers’ model 所述,应用程序级别对应于在 EL0 执行。架构定义了一组缓存维护指令,软件可以使用这些指令来管理缓存一致性。在更高异常级别执行的软件可以允许在 EL0 使用部分此类功能,具体如下:
当 SCTLR_EL1.UCI 的值为 1 时
在 EL0 执行的软件可以访问:
- 数据缓存维护指令
DC CVAU、DC CVAC、DC CVAP、DC CVADP和DC CIVAC。请参见 The data cache maintenance instruction ( DC )。 - 指令缓存维护指令
IC IVAU。请参见 The instruction cache maintenance instruction ( IC )。
尝试执行这些指令可能会产生权限故障(Permission fault),如 Permission fault 中所述。
当 SCTLR_EL1.UCT 的值为 1 时
在 EL0 执行的软件可以访问缓存类型寄存器。请参见 CTR_EL0。
当 SCTLR_EL1.DZE 的值为 1 时
在 EL0 执行的软件可以访问数据缓存清零指令 DC ZVA。请参见 Data cache zero instruction。
SCTLR_EL1.{UCI, UCT, DZE} 控制字段仅可由在 EL1 或更高异常级别执行的软件访问。
当 HCR_EL2.{E2H, TGE} 的有效值为 {1, 1} 时,控制字段 {UCI, UCT, DZE} 位于 SCTLR_EL2 中。
当相应的 SCTLR_EL1 控制字段的值为 0 时,上述功能在 EL0 下为未定义(UNDEFINED)。
B2.7.4 缓存对应用程序员的影响(Implication of caches for the application programmer)
在正常操作中,缓存对应用程序员基本透明。然而,当缓存一致性遭到破坏时,缓存就会变得可见。这种破坏可能发生在以下情况:
- 当内存位置被系统中不使用硬件一致性管理的其他代理更新时。
- 当应用程序软件所做的内存更新必须在未使用硬件一致性管理的情况下对系统中的其他代理可见时。
例如:
- 在没有 DMA 访问硬件一致性管理的系统中,当 DMA 控制器读取保存在 PE 数据缓存中的内存位置时,如果 PE 已在数据缓存中写入了新数据,但 DMA 控制器读取的是内存中保存的旧数据,就会发生一致性破坏。
- 在哈佛缓存实现中,存在独立的指令缓存和数据缓存。当新的指令数据已写入数据缓存,但指令缓存仍包含旧的指令数据时,就会发生一致性破坏。
B2.7.4.1 数据一致性问题(Data coherency issues)
软件可以通过以下方式确保缓存的数据一致性:
- 不使用可能产生一致性问题的缓存。可以通过以下方式实现:
- 使用不可缓存(Non-cacheable)的内存,或在某些情况下使用写通可缓存(Write-Through Cacheable)的内存。
- 不在系统中启用缓存。
- 使用缓存维护指令在软件中管理一致性问题。请参见 Application level access to functionality related to caches。
- 使用硬件一致性机制确保不同可共享性域内的观察者对可缓存位置的访存数据保持一致,请参见 Non-shareable Normal memory 和 Shareable, Inner Shareable, and Outer Shareable Normal memory。
注意: 这些硬件一致性机制的性能高度依赖于具体实现(IMPLEMENTATION SPECIFIC)。在某些实现中,该机制会抑制缓存可共享位置的能力。在其他实现中,缓存一致性硬件可以在缓存中保存数据,同时管理可共享性域内各观察者之间的一致性。
注意: 并非所有这些机制都可供在 EL0 运行的软件直接使用,且可能需要与在更高异常级别运行的软件进行交互。
B2.7.4.2 数据访问与指令访问之间的同步和一致性问题(Synchronization and coherency issues between data and instruction accesses)
指令在当前执行点之前被预取多远是由实现定义的(IMPLEMENTATION DEFINED)。这种预取可以是固定数量或动态变化的指令数量,并且可以遵循任意或所有可能的未来执行路径。对于所有类型的内存:
- PE 可能自该 PE 上的上一次上下文同步事件(Context Synchronization event)以来的任何时刻,从内存中预取了指令。
- 以这种方式预取的任何指令可能会被执行多次(如果程序执行需要),而无需从内存中重新预取。在没有上下文同步事件的情况下,此类指令可能被执行的次数(无需从内存中重新预取)没有限制。
Arm 架构要求硬件确保指令缓存与内存之间的一致性,即使对于共享内存的位置也是如此。当满足以下条件时,对某个可共享性域的指令预取而言,一次写入操作已达到一致:
CTR_EL0.{DIC, IDC} == {0, 0} 已写入的位置已从数据缓存清理(clean)到统一点(PoU),且该清理操作对该可共享性域已完成。随后,该位置已从指令缓存失效(invalidate)到统一点(PoU),且该失效操作对该可共享性域已完成。
CTR_EL0.{DIC, IDC} == {0, 1} 写入操作对该可共享性域已完成。随后,该位置已从指令缓存失效到统一点(PoU),且该失效操作对该可共享性域已完成。
CTR_EL0.{DIC, IDC} == {1, 1} 写入操作对该可共享性域已完成。
注意: 从微架构角度而言,这意味着在实现中以下两种情况不可能同时为真:
- 经过从内存预取的延迟后,指令队列中的条目可能乱序写入。
- 对于某个实现:
- 当
CTR_EL0.DIC == 0时,如果指令队列中存在一个未完成的条目,则指令队列中后续的条目不会受其他核心的IC IVAU指令影响。- 当
CTR_EL0.DIC == 1时,如果对保存在队列中的位置进行写入,而指令队列中有一个较早的未完成条目,则指令队列中的条目不会因此被失效。
CTR_EL0.{DIC, IDC} 排序含义的完整定义由形式化并发模型定义的排序要求(Ordering requirements defined by the formal concurrency model) 正式涵盖,本节中的信息无意与那部分内容相矛盾。
如果软件需要指令执行与内存之间的一致性,则必须使用上下文同步事件和缓存维护指令来管理该一致性。以下代码序列可用于允许 PE 执行同一 PE 已写入的代码。
1 | ; 同一内部可共享域内数据访问和指令访问的一致性示例。 |
注意:
- 如果在向某个位置写入数据与执行该位置的指令之间未执行此序列,则指令缓存与内存之间缺乏一致性意味着实际执行的指令可能是旧指令,也可能是更新后的指令,且在执行过程中使用哪个指令可能会任意变化。软件不得在同步序列执行之前假设——即使已看到更新后的指令——旧指令就不会再被看到。
- 对于不可缓存(Non-cacheable)或写通(Write-Through)访问,不需要执行数据缓存清理指令。但是,仍然需要执行指令缓存失效指令,因为 Armv8 AArch64 架构允许不可缓存的访问保存在指令缓存中。请参见 Non-cacheable accesses and instruction caches。
- 当修改代码的执行线程与执行代码的线程是同一线程时,可以使用此代码。Arm 架构限制了在一个线程正在被另一个线程修改时可以执行的指令集,而不需要显式同步。请参见 Concurrent modification and execution of instructions。
- 系统软件通过设置
SCTLR_EL1.UCI控制这些缓存维护指令是否可供应用程序级别使用。
B2.7.5 预取到缓存(Prefetching into cache)
Arm 架构提供了内存系统提示指令 PRFM、PRFUM、RPRFM、LDNP 和 STNP,软件可以使用这些指令向硬件传达内存位置的预期使用方式。内存系统可以通过采取预期会加速内存访问(如果访问发生)的措施来响应。这些内存系统提示的效果是由实现定义的(IMPLEMENTATION DEFINED)。通常,实现会利用这些信息将数据或指令位置带入缓存。
预取指令是提示(hints),因此实现可以将其视作 NOP(空操作)而不影响设备的功能行为。这些指令不会产生同步数据中止异常(Data Abort),但在异常情况下,产生的内存系统操作可能会触发异步外部中止(External abort),并通过 SError 异常来处理。更多信息,请参见 ISS encoding for an exception from a Data Abort。
PrefetchHint {} 定义了预取提示的类型。
Hint_Prefetch() 函数向内存系统发出信号,表明对指定地址的指定提示类型的内存访问可能在不久的将来发生。内存系统可能会采取某些措施来加速这些访问的实际发生,例如将指定地址预取到一个或多个缓存中(由最内层缓存级别目标和非临时提示流指示)。
关于 PRFM、PRFUM、RPRFM 以及向内存系统提供提示的加载/存储指令的更多信息,请参见 Prefetch memory 和 Load/store SIMD and floating-point non-temporal pair。关于向内存系统提供提示的 SVE PRF* 指令的更多信息,请参见 Predicated non-contiguous element accesses。
B2.8 对齐支持(Alignment support)
B2.8 对齐支持
本节描述对齐支持。包含以下子节:
- 指令对齐(Instruction alignment)。
- 数据访问的对齐(Alignment of data accesses)。
B2.8.1 指令对齐
A64指令必须字对齐。
尝试从未对齐的位置取指令会导致PC对齐错误(PC alignment fault)。参见PC对齐检查(PC alignment checking)。
B2.8.2 数据访问的对齐
当执行加载或存储单个或多个寄存器的指令时,如果适用于当前异常级别的SCTLR_ELx.A的值为1,则在以下任一情况下产生对齐错误(Alignment fault):
- 对于Load-Exclusive、Store-Exclusive以及原子(Atomic)指令,被访问的地址未按整体访问大小对齐。
- 对于所有其他指令,被访问的地址未按所访问数据元素的大小对齐。
如果实现了FEAT_LSE2,没有独占或原子行为的Load-Acquire/Store-Release指令在同时满足以下条件时产生对齐错误:
- 并非所有内存访问的字节都位于一个16字节对齐的16字节量内。
- 适用于当前异常级别的SCTLR_ELx.nAA的值为0。
对于任何类型的设备内存(Device memory)的未对齐访问:
- 如果该内存位置不支持未对齐访问,则产生对齐错误。
- 如果该内存位置支持未对齐访问,那么若相同访问在正常内存(Normal memory)上不会产生对齐错误,则是否产生对齐错误是由实现定义的(IMPLEMENTATION DEFINED)。
B2.8.2.1 对正常内存(Normal memory)的未对齐访问
对正常内存的未对齐访问的行为取决于以下所有因素:
- 引起内存访问的指令。
- 被访问内存的内存属性。
- SCTLR_ELx.{A, nAA}的值。
- 是否实现了FEAT_LSE2。
B2.8.2.1.1 单个或多个寄存器的加载或存储
对于所有加载或存储单个或多个寄存器的指令,但不包括Load-Exclusive、Store-Exclusive、Load-Acquire/Store-Release、原子(Atomic)以及SETG*内存复制和内存设置(Memory Copy and Memory Set)指令,如果被访问的地址未按所访问数据元素的大小对齐,则:
当适用于当前异常级别的SCTLR_ELx.A的值为1时,产生对齐错误。
当适用于当前异常级别的SCTLR_ELx.A的值为0时:
- 执行未对齐访问。
- 如果未实现FEAT_LSE2,则不保证该访问是单拷贝原子(single-copy atomic)的,除非在字节访问级别。
- 如果实现了FEAT_LSE2:
- 如果内存访问的所有字节都位于一个16字节对齐的16字节量内,并且访问的是正常内存(Normal)、内部写回(Inner Write-Back)、外部写回(Outer Write-Back)、可缓存(Cacheable)、可共享(Shareable)内存,则该内存访问是单拷贝原子(single-copy atomic)的。对于LDNP、LDP或STP指令,整个内存访问将是单拷贝原子的。
- 如果被访问内存的所有字节并非都位于一个16字节对齐的16字节量内,或者访问的不是正常内存、内部写回、外部写回、可缓存、可共享内存,则不保证该访问是单拷贝原子(single-copy atomic)的,除非在字节访问级别。
对于这些指令,未对齐访问的定义基于被访问元素的大小,而不是内存访问的整体大小。这会影响SIMD和SVE元素及结构体的加载和存储,以及加载/存储指令对(load/store pair instructions)。
对于有预测(predicated)的SVE向量元素和结构体加载或存储指令,对齐检查基于内存元素访问大小,而不是向量元素大小。
对于有预测(predicated)的SVE向量元素和结构体加载或存储指令,非活跃(Inactive)元素不会引起对齐错误。
对于无预测(unpredicated)的SVE向量寄存器加载或存储指令,基地址按16字节对齐进行检查。
对于无预测(unpredicated)的SVE谓词寄存器加载或存储指令,基地址按2字节对齐进行检查。
B2.8.2.1.2 Load-Exclusive/Store-Exclusive及原子(Atomic)指令
如果未实现FEAT_LSE2且适用于当前异常级别的SCTLR_ELx.A的值为0,则当被访问的地址未按访问的整体大小对齐时,Load-Exclusive/Store-Exclusive及原子(Atomic)指令(包括带有获取或释放语义的指令)会产生对齐错误。
如果实现了FEAT_LSE2,则:
- 如果内存访问的所有字节都位于一个16字节对齐的16字节量内,并且访问的是正常内存、内部写回、外部写回、可缓存、可共享内存,则执行未对齐访问。
- 如果内存访问的所有字节并非都位于一个16字节对齐的16字节量内,或者内存访问的不是正常内存、内部写回、外部写回、可缓存、可共享内存,则是在以下两者中作受限不可预测(CONSTRAINED UNPREDICTABLE)的选择:
- 执行满足指令所有语义的未对齐访问。
- 产生对齐错误。
如果执行了内存访问,则该访问是单拷贝原子(single-copy atomic)的。
对于这些指令,未对齐访问的定义基于整体访问大小。
如果实现了FEAT_LS64,当单拷贝原子64字节指令访问未按64字节对齐的内存位置时,无论SCTLR_ELx.A的值如何,始终会产生对齐错误。
如果实现了FEAT_THE,读-检查-写(Read-Check-Write)指令RCW和读-检查-写软件(Read-Check-Write Software)指令RCWS,在被访问地址未按整体访问大小对齐时会产生对齐错误,无论SCTLR_ELx.A的值如何。
B2.8.2.1.3 非原子Load-Acquire/Store-Release指令
对于不具有独占或原子行为的Load-Acquire/Store-Release指令,当被访问地址未按所访问数据元素的大小对齐且适用于当前异常级别的SCTLR_ELx.A的值为0时:
如果未实现FEAT_LSE2,则这些指令产生对齐错误。
如果实现了FEAT_LSE2,则:
- 如果内存访问的不是正常内存、内部写回、外部写回、可缓存、可共享内存,则是在以下两者中作受限不可预测(CONSTRAINED UNPREDICTABLE)的选择:
- 执行未对齐访问,不保证是单拷贝原子(single-copy atomic)的,除非在字节访问级别。
- 产生对齐错误。
- 如果内存访问的所有字节并非都位于一个16字节对齐的16字节量内,且适用于当前异常级别的SCTLR_ELx.nAA的值为1,则执行未对齐访问,不保证是单拷贝原子(single-copy atomic)的,除非在字节访问级别。
译者注: 上述条件中,被访问地址未按数据元素大小对齐且SCTLR_ELx.A=0是前提条件。此分支中”SCTLR_ELx.nAA=1”意味着允许非对齐访问但不需要原子性保证。
在这种情况下,当执行访问时,它满足指令的所有语义,但架构未定义由该单条指令定义的不同访问事务之间的相对顺序。
- 如果内存访问的所有字节都位于一个16字节对齐的16字节量内,并且访问的是正常内存、内部写回、外部写回、可缓存、可共享内存,则执行满足指令所有语义的未对齐访问。
译者注:
- 与自然对齐的访问相比,未对齐访问通常需要更多的时钟周期才能完成。
- 在字节级别以上非单拷贝原子(non-single-copy atomic)的操作可以在其进行的任何内存访问上中止,并且可以在多个访问上中止。这意味着跨越页面边界的未对齐访问可以在页面边界的任一侧产生中止。
B2.8.2.1.4 内存复制(Memory Copy)和内存设置(Memory Set)指令
对于SETG*指令:
- 无论SCTLR_ELx.A的值如何,都会进行对齐检查。
- 如果Xn不是16的倍数,则产生对齐错误。
- 如果Xd未按16的倍数对齐,则产生对齐错误。
更多信息请参见各个SETG*指令的描述。
B2.9 字节序支持(Endian support)

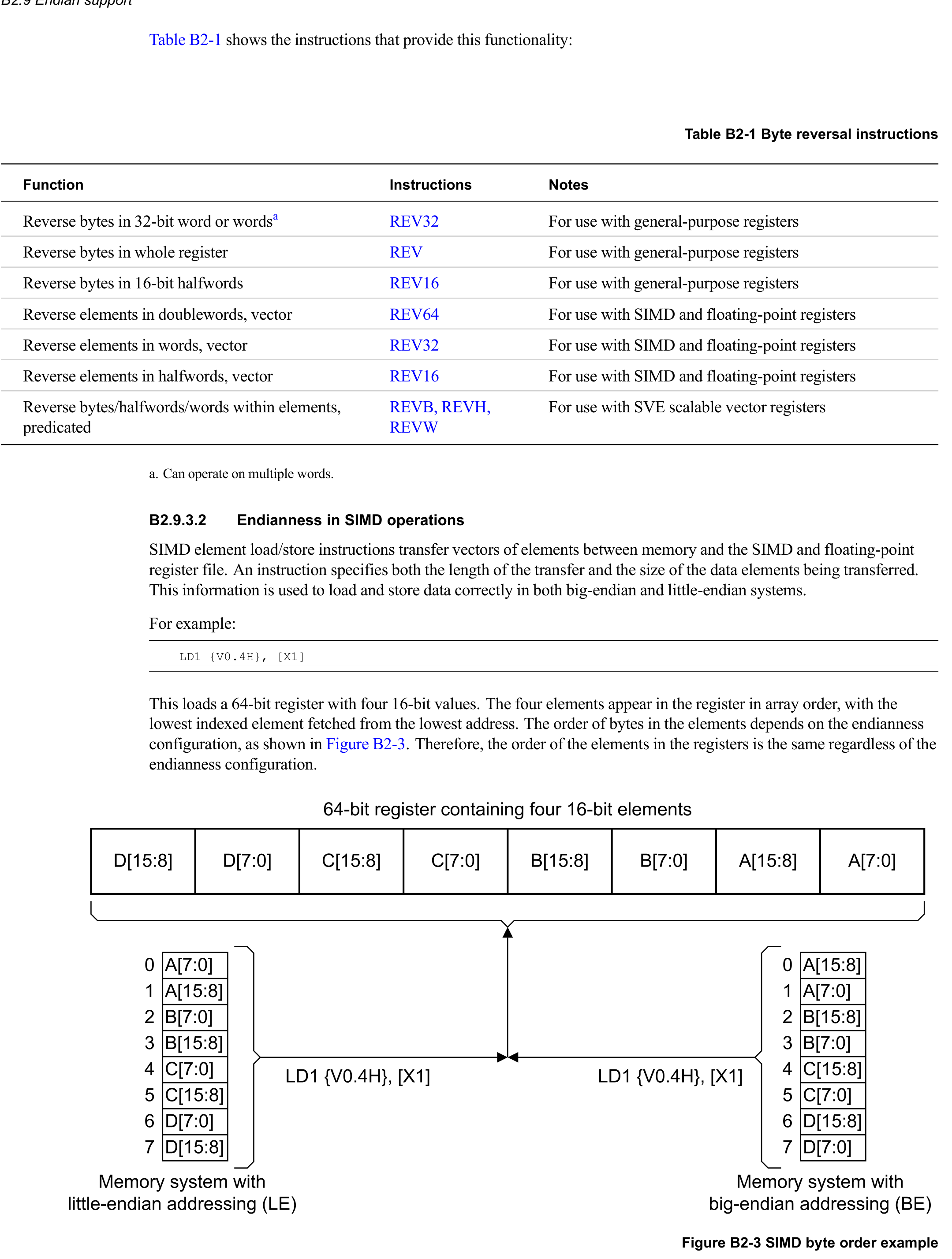
B2.9 字节序支持
关于Arm架构中字节序(endianness)的通用描述,说明了Arm架构中字节序与内存寻址之间的关系。
以下小节描述了架构支持的字节序方案:
- 指令字节序(Instruction endianness)。
- 数据字节序(Data endianness)。
- 内存映射外设的字节序(Endianness of memory-mapped peripherals)。
B2.9.1 Arm架构中字节序的通用描述
本节仅描述内存寻址以及字节序对最大128位四字(quadword)数据元素的影响。但本描述可扩展应用于更大的数据元素。
对于地址A,图B2-2展示了大端(big-endian)和小端(little-endian)内存系统中以下各项之间的关系:
- 地址A处的四字(quadword)。
- 地址A和A+8处的双字(doubleword)。
- 地址A、A+4、A+8和A+12处的字(word)。
- 地址A、A+2、A+4、A+6、A+8、A+10、A+12和A+14处的半字(halfword)。
- 地址A、A+1、A+2、A+3、A+4、A+5、A+6、A+7、A+8、A+9、A+10、A+11、A+12、A+13、A+14和A+15处的字节(byte)。
图B2-2中的术语定义如下:
| 术语 | 定义 |
|---|---|
| B_A | 地址A处的字节(Byte at address A) |
| HW_A | 地址A处的半字(Halfword at address A) |
| MSByte | 最高有效字节(Most significant byte) |
| LSByte | 最低有效字节(Least significant byte) |
ARM DDI 0487 Copyright © 2013-2026 Arm Limited或其关联公司。保留所有权利。 B2-313
M.b 非保密
图B2-2 字节序关系(Endianness relationships)
大端和小端映射方案决定了四字、双字、字或半字中字节的解释顺序。例如,从地址0x1000加载一个字始终会访问内存位置0x1000、0x1001、0x1002和0x1003处的字节。字节序映射方案决定了这4个字节的权重(即哪一个是最高有效字节,哪一个是最低有效字节)。
B2.9.2 指令字节序(Instruction endianness)
A64指令具有固定的32位长度,并且始终为小端。
B2.9.3 数据字节序(Data endianness)
SCTLR_EL1.E0E(可在EL1或更高异常级别配置)决定了在EL0执行时的数据字节序。当HCR_EL2.{E2H, TGE}的有效值为{1, 1}时,控制权来自SCTLR_EL2.E0E。
用于字节序转换的数据大小:
- 对于SIMD和浮点寄存器以及通用寄存器的加载和存储,为加载或存储的数据值的大小。
- 对于SIMD元素和数据结构的加载和存储,为加载或存储的数据元素的大小。更多信息请参见”SIMD操作中的字节序”(Endianness in SIMD operations)。
注意: 这意味着Armv8架构引入了对128位字节序转换的要求。
B2.9.3.1 在通用寄存器、SIMD和浮点寄存器或SVE可扩展向量寄存器中反转字节的指令
应用程序或设备驱动程序可能需要与内存映射外设寄存器或共享内存结构进行接口交互,而这些外设或结构的字节序可能与内部数据结构不同。同样,操作系统的字节序也可能与外设寄存器或共享内存不匹配。在这些情况下,PE(处理单元)需要一种高效的方法来显式转换数据的字节序。
表B2-1显示了提供此功能的指令:
表B2-1 字节反转指令(Byte reversal instructions)
| 功能 | 指令 | 说明 |
|---|---|---|
| 在32位字或多个字中反转字节^a | REV32 |
用于通用寄存器 |
| 在整个寄存器中反转字节 | REV |
用于通用寄存器 |
| 在16位半字中反转字节 | REV16 |
用于通用寄存器 |
| 在双字中反转元素(向量) | REV64 |
用于SIMD和浮点寄存器 |
| 在字中反转元素(向量) | REV32 |
用于SIMD和浮点寄存器 |
| 在半字中反转元素(向量) | REV16 |
用于SIMD和浮点寄存器 |
| 在元素内反转字节/半字/字(带预测) | REVB, REVH, REVW |
用于SVE可扩展向量寄存器 |
a. 可操作多个字。
B2.9.3.2 SIMD操作中的字节序(Endianness in SIMD operations)
SIMD元素加载/存储指令在内存与SIMD和浮点寄存器文件之间传输向量元素。指令同时指定传输长度和所传输数据元素的大小。该信息用于在大端和小端系统中正确加载和存储数据。
例如:
1 | LD1 {V0.4H}, [X1] |
这条指令将一个64位寄存器加载四个16位值。这四个元素以数组顺序出现在寄存器中,最低索引的元素从最低地址获取。元素中字节的顺序取决于字节序配置,如图B2-3所示。因此,无论字节序配置如何,寄存器中元素的顺序是相同的。
图B2-3 SIMD字节序示例(SIMD byte order example)
BigEndian()伪代码函数确定当前数据的字节序。
BigEndianReverse()伪代码函数反转位串的字节序。
BigEndian()和BigEndianReverse()函数在A架构伪代码(A-profile Architecture Pseudocode)中定义。
B2.9.3.3 SVE操作中的字节序(Endianness in SVE operations)
RVDGQK SIMD加载和存储指令关于字节和元素顺序的规则适用于SVE加载和存储指令。
IRFQJP 附加规则适用于SVE加载和存储指令执行的内存访问的数据字节序。
RCNKCL 对于带预测的SVE向量元素和结构加载/存储指令,使用内存元素访问大小(memory element access size)执行字节序转换。向量元素的大小不用于字节序转换。
RQHXPL 对于无预测(unpredicated)的SVE向量寄存器加载/存储指令,向量字节元素按递增元素编号顺序传输,不进行任何字节序转换。
RRWLXY 对于无预测的SVE谓词寄存器(predicate register)加载/存储指令,谓词中的每8位作为一个字节,按递增元素编号顺序传输,不进行任何字节序转换。
RYGSBQ 执行SVE加载指令时,字节序转换发生在任何符号扩展或零扩展到向量元素之前。
RKYRQW 执行SVE存储指令时,字节序转换发生在任何从向量元素截断(truncation)到内存元素访问大小之后。
B2.9.4 内存映射外设的字节序(Endianness of memory-mapped peripherals)
Arm架构中定义的所有内存映射外设必须为小端。
适用此要求的外设包括:
- 调试器或交叉触发接口(Cross Trigger Interface)的内存映射寄存器接口,请参见”关于外部调试寄存器”(About the External Debug Registers)。
- 通用定时器(Generic Timer)系统级实现的内存映射寄存器接口,请参见”通用定时器的系统级实现”(System Level Implementation of the Generic Timer)。
- 性能监视器(Performance Monitors)的内存映射寄存器接口,请参见”性能监视器的推荐外部接口”(Recommended External Interface to the Performance Monitors)。
- 活动监视器(Activity Monitors)的内存映射寄存器接口,请参见”活动监视器的推荐外部接口”(Recommended External Interface to the Activity Monitors)。
- 内存系统资源分区与监控(MPAM)架构的内存映射寄存器接口,请参见Arm(R)内存系统资源分区与监控(MPAM)系统组件规范(ARM IHI 0099)。
- Arm通用中断控制器(Generic Interrupt Controller, GIC)架构的内存映射寄存器接口,请参见ARM(R)通用中断控制器架构规范,GIC架构版本3和版本4。
- Arm跟踪组件(trace component)的内存映射寄存器接口。例如,请参见Arm(R)嵌入式跟踪宏单元架构规范ETMv4。
ARM DDI 0487 Copyright © 2013-2026 Arm Limited或其关联公司。保留所有权利。 B2-316
M.b 非保密
译者注:
- 本节B2.9的标题”Endian support”译为”字节序支持”。字节序(endianness)也称为端序或尾序,指多字节数据在内存中存放时字节的排列顺序。小端(little-endian)表示最低有效字节位于最低地址,大端(big-endian)表示最高有效字节位于最低地址。
- A64指令集固定为32位长且始终为小端,这是Armv8/Armv9架构A64指令集的固定特性。
SCTLR_EL1.E0E中的E0E表示”Exception level 0 Endianness”,控制EL0(用户态)的数据字节序。- SVE(Scalable Vector Extension)是AArch64状态下的可扩展向量扩展,支持可变长度向量。
- 文中出现的RVDGQK、IRFQJP等大写字母组合为ARM文档的标签ID,用于交叉引用和合规性追踪,保留原文不译。
B2.10 内存类型和属性(Memory types and attributes)
内存中地址的访问排序(称为内存顺序模型)由内存属性(memory attributes)定义。以下各节描述该模型:
- 普通内存(Normal memory)
- 设备内存(Device memory)
- 内存访问限制(Memory access restrictions)
B2.10.1 普通内存(Normal memory)
普通内存类型属性适用于系统中的大部分内存。它表示架构允许硬件对这些位置进行推测性数据读取访问(Speculative data read accesses),无论这些位置的访问权限如何。
普通内存类型具有以下属性:
- 对具有Normal属性的内存位置的**显式内存写效果(Explicit Memory Write Effect)**在有限时间内完成。
- 对具有Normal内存类型且在内核(Inner)和外核(Outer)可缓存性上均为不可缓存(Non-cacheable)或写通可缓存(Write-Through cacheable)的内存位置的显式内存写效果,必须在有限时间内到达该位置在内存系统中的端点(endpoint)。对同一位置的两次写入(其中至少一次使用Normal内存类型),除非两次写入之间存在ordered-before关系,否则可能在到达端点之前被合并。就这一要求而言,常规内存(Conventional memory)中位置的端点是一致性点(PoC)。
译者注: PoC(Point of Coherency,一致性点)是内存系统中所有观察者都能看到数据一致版本的那个点。在PoC之前,不同缓存可能持有同一内存位置的不同副本;在PoC处,所有缓存和内存的一致性得到保证。这是缓存一致性协议中用于确定写操作何时全局可见的关键概念。
- 如果系统配置为生成非对齐访问,则可以对Normal内存进行非对齐内存访问。
- 不要求PE之外的内存系统能够识别多寄存器加载/存储指令所访问的元素大小。参见 访问Normal内存的多寄存器加载和存储。
- 如果加载或存储指令执行一系列内存访问(而非按照单次拷贝原子性规则定义的一次单次拷贝原子访问),这些访问可能因执行该加载或存储指令而多次发生。
Note(注意)
对所有内存类型,禁止对其他观察者可见的写推测(Write speculation)。
Note(注意)
- Normal内存属性适用于满足**幂等性(idempotent)**的内存位置,即具有以下所有属性:
- 读访问可以重复执行且无副作用。
- 重复的读访问返回最后一次写入被读资源的值。
- 读访问可以获取额外的内存位置且无副作用。
- 写访问可以重复执行且无副作用,前提是在重复写入之间或由于异常(如本节所述),被访问位置的内容未发生变化。
- 支持非对齐访问。
- 访问可以在到达目标内存系统之前被合并。
- Normal内存允许推测性读取,并可能受到中间缓冲和数据转发的影响。如果将非幂等内存位置映射为Normal内存,可能出现以下情况:
- 内存访问返回**UNKNOWN(未知)**值。
- 对内存映射外设产生**UNPREDICTABLE(不可预测)**影响。
- 如 Arm架构中的原子性 所述,生成一系列访问的指令可能因在该系列访问过程中发生异常而被放弃。从异常返回后,指令重新开始执行,因此一个或多个内存位置可能被多次访问。这可能导致对某个位置的重复写入访问,而该位置在两次写入之间已被改变。
对于对Normal内存的访问,需要DMB指令来确保所需的排序。
以下各节描述Normal内存的其他属性:
- 可共享Normal内存(Shareable Normal memory)
- 不可共享Normal内存(Non-shareable Normal memory)
- Normal内存的可缓存性属性(Cacheability attributes for Normal memory)
另请参见:
- 访问Normal内存的多寄存器加载和存储
- Arm架构中的原子性
- 内存屏障
- 指令的并发修改和执行
B2.10.1.1 可共享Normal内存(Shareable Normal memory)
Normal内存位置具有一个可共享性属性(Shareability attribute),取以下之一:
- 内部可共享(Inner Shareable),表示适用于内部可共享性域。
- 外部可共享(Outer Shareable),表示适用于内部可共享性域和外部可共享性域两者。
- 不可共享(Non-shareable)。
译者注: 缓存一致性(cache coherency)是指在多处理器系统中,确保每个PE(处理单元)看到的共享内存数据是一致的。硬件一致性协议(如MESI、MOESI)自动维护这种一致性,而软件可通过缓存维护指令(DC CVAC等)和屏障指令(DMB/DSB)进行手动管理。Arm架构通过可共享性属性(Shareability)来定义硬件需要维护一致性的范围。
可共享性属性定义了硬件必须强制执行的该位置的数据一致性要求。它们不影响指令获取的一致性要求,参见 数据和指令访问之间的同步与一致性问题。
Note(注意)
- 系统设计人员可以使用可共享性属性来指定Normal内存中需要保持一致性的位置。但是,软件开发人员不得假设将内存位置指定为不可共享(Non-shareable)就允许软件在共享内存系统中假定不同PE之间该位置的不一致性。这种假设在不同的多处理实现之间是不可移植的,因为这些实现可能使用可共享性属性。任何多处理实现都可能实现不同处理元素之间固有地共享的缓存。
- 本架构假设使用相同操作系统或虚拟机监控程序的所有PE都位于同一个内部可共享性域中。
B2.10.1.1.1 可共享、内部可共享和外部可共享Normal内存(Shareable, Inner Shareable, and Outer Shareable Normal memory)
Arm架构将系统抽象为一系列内部(Inner)和外部(Outer)可共享性域。
每个内部可共享性域包含一组观察者,对于该集合中任何成员发出的具有内部可共享属性的数据访问,该集合的每个成员之间在数据上保持一致。
译者注: 可共享性域(Shareability domain)定义了硬件缓存一致性的作用范围。内部可共享性域通常对应于运行在同一操作系统或虚拟机监控程序下的所有PE(处理单元),而外部可共享性域涵盖更大范围(如多路服务器系统中所有处理器)。Non-shareable表示不需要硬件一致性,软件需自行管理缓存。
每个外部可共享性域包含一组观察者,对于该集合中任何成员发出的具有外部可共享属性的数据访问,该集合的每个成员之间在数据上保持一致。
以下属性也成立:
- 每个观察者仅是一个内部可共享性域的成员。
- 每个观察者仅是一个外部可共享性域的成员。
- 内部可共享性域中的所有观察者始终是同一个外部可共享性域的成员。这意味着内部可共享性域是外部可共享性域的子集,但不要求是真子集。
Note(注意)
- 由于对不可缓存(Non-cacheable)位置的所有数据访问对所有观察者都是数据一致的,因此不可缓存位置始终被视为外部可共享(Outer Shareable)。
- 内部可共享性域预期是由单个虚拟机监控程序或操作系统控制的一组PE。
可共享性属性的使用细节是**系统特定(system-specific)**的。示例B2-1展示了它们可能的使用方式。
示例 B2-1 可共享性属性的使用
在一个实现中,某个具有两个PE集群的子系统有以下要求:
- 在每个集群内,该集群中PE的数据缓存或统一缓存对于所有对具有内部可共享属性的内存位置的数据访问都是透明的。
- 但是,在两个集群之间,缓存:
- 对于仅具有内部可共享属性的数据访问,不要求保持一致。
- 对于具有外部可共享属性的数据访问,保持一致。
在该系统中,每个集群对于内部可共享属性位于不同的可共享性域中,但子系统的所有组件对于外部可共享属性位于相同的可共享性域中。
一个系统可能实现两个这样的子系统。如果其中一个子系统的数据缓存或统一缓存对来自另一个子系统的访问不透明,则该系统具有两个外部可共享性域。
具有两个级别的可共享性意味着系统设计人员可以减少那些不需要成为外部可共享性域一部分的共享内存位置的性能和功耗开销。
对于可共享Normal内存,Load-Exclusive和Store-Exclusive同步原语会考虑同一可共享性域中多个观察者访问的可能性。
B2.10.1.2 不可共享Normal内存(Non-shareable Normal memory)
对于Normal内存位置,不可共享属性标识了可能仅由单个PE访问的Normal内存。
具有不可共享属性的Normal内存位置不要求硬件使不同观察者的数据访问保持一致,除非该内存是不可缓存的(Non-cacheable)。对于不可共享位置,如果其他观察者共享内存系统,软件必须使用缓存维护指令(如果缓存的存在可能导致观察者之间通信时的一致性问题)。此缓存维护要求是对确保内存排序所需的屏障操作的补充。
对于不可共享Normal内存,Load-Exclusive和Store-Exclusive同步原语是否考虑多个观察者访问的可能性是**实现定义(IMPLEMENTATION DEFINED)**的。
B2.10.1.3 Normal内存的可缓存性属性(Cacheability attributes for Normal memory)
除了是外部可共享、内部可共享或不可共享之外,每个Normal内存区域还被分配一个可缓存性属性(Cacheability attribute),取以下之一:
- 写通可缓存(Write-Through Cacheable)
- 写回可缓存(Write-Back Cacheable)
- 不可缓存(Non-cacheable)
此外,对于写通可缓存和写回可缓存的Normal内存区域:
- 一个区域可能被分配用于读和写访问的缓存分配提示(cache allocation hints)。
- 缓存分配提示是否可以具有**瞬态(Transient)或非瞬态(Non-transient)的附加属性是实现定义(IMPLEMENTATION DEFINED)**的。
更多信息请参见 可缓存性、缓存分配提示和缓存瞬态提示。
内存位置可以被标记为具有不同的可缓存性属性,例如在使用VA到PA映射中的别名时:
- 如果属性仅在缓存分配提示上不同,这不影响对该位置的访问行为。
- 对于其他情况,请参见 不匹配的内存属性。
可缓存性属性提供了一种与位于内存区域可共享性域之外的观察者进行一致性控制的机制。在某些情况下,使用写通可缓存或不可缓存内存区域可能比使用硬件一致性机制或缓存维护例程提供更好的一致性控制机制。为此,架构对不可缓存或写通可缓存内存要求以下属性:
- 由访问缓存级别内部内存系统的观察者完成的、对某个缓存级别为不可缓存或写通可缓存的内存位置的写入,无需显式缓存维护即可对所有访问该缓存级别外部内存系统的观察者可见。
- 由访问缓存级别外部内存系统的观察者完成的、对某个缓存级别为不可缓存的内存位置的写入,无需显式缓存维护即可对所有访问该缓存级别内部内存系统的观察者可见。
- 对于对不可缓存Normal内存的访问,DMB指令在**实现定义(IMPLEMENTATION DEFINED)大小的单个外设或内存块上的所有访问之间引入屏障有序优先(Barrier-ordered-before)**关系。更多信息请参见 排序关系。
Note(注意)
实现可以使用缓存分配提示来指示缓存的潜在性能收益。例如,程序员可能知道某块内存不会被再次访问,因此更适合视为不可缓存。仅在缓存分配提示上有所不同的内存区域之间的区别仅作为性能提示存在。
对于Normal内存,Arm架构提供了为两个概念性的缓存级别(内核缓存和外核缓存)独立定义的可缓存性属性。这些概念性缓存级别与实现的物理缓存级别之间的关系是**实现定义(IMPLEMENTATION DEFINED)**的,并且可能与内部和外部可共享性域之间的边界不同。但是:
- 内核(Inner) 指最内层的缓存,即最接近PE的缓存,并且始终包含最低级别的缓存。
- 由内核可缓存性属性控制的任何缓存都不能位于由外核可缓存性属性控制的缓存之外。
- 一个实现可能没有任何外核缓存。
示例B2-2、示例B2-3和示例B2-4描述了具有三个缓存级别(L1到L3)的系统的可能实现方式。
Note(注意)
- L1缓存是最接近PE的级别,参见 内存层次结构。
- 在管理一致性时,系统设计必须同时考虑内核和外核可缓存性属性以及可共享性属性。这是因为即使在一个概念性级别具有不可缓存属性时,硬件可能仍需要管理另一个概念性级别缓存的一致性。
示例 B2-2 具有两个内核缓存级别和一个外核缓存级别的实现
实现系统中的三个缓存级别L1到L3,其中:
- 内核可缓存性属性应用于L1和L2缓存。
- 外核可缓存性属性应用于L3缓存。
示例 B2-3 具有三个内核缓存级别且无外核缓存级别的实现
实现系统中的三个缓存级别L1到L3,其中内核可缓存性属性应用于L1、L2和L3缓存。不使用外核可缓存性属性。
示例 B2-4 具有一个内核缓存级别和两个外核缓存级别的实现
实现系统中的三个缓存级别L1到L3,其中:
- 内核可缓存性属性应用于L1缓存。
- 外核可缓存性属性应用于L2和L3缓存。
B2.10.1.4 访问Normal内存的多寄存器加载和存储(Multi-register loads and stores that access Normal memory)
对于所有从某个异常级别加载或存储多个通用寄存器的指令,不要求PE之外的内存系统能够识别这些加载或存储指令所访问的元素大小。
对于所有从某个异常级别加载或存储多个通用寄存器的指令,寄存器被访问的顺序不由架构定义。
对于所有从某个异常级别加载或存储一个或多个SVE或Advanced SIMD&FP寄存器的指令,不要求PE之外的内存系统能够识别这些加载或存储指令所访问的元素大小。
B2.10.2 设备内存(Device memory)
**设备内存类型属性(Device memory type attributes)**定义了这样一些内存位置:对这些位置的访问可能导致副作用,或者加载操作返回的值可能因执行的加载次数而变化。通常,设备内存属性用于内存映射外设和类似位置。
Armv8设备内存的属性如下:
| 属性 | 标识 | 说明 |
|---|---|---|
| 汇聚(Gathering) | G 或 nG | 参见 汇聚 |
| 重排序(Reordering) | R 或 nR | 参见 重排序 |
| 早期写确认(Early Write Acknowledgement) | E 或 nE | 参见 早期写确认 |
译者注: 设备内存的三个属性(G/R/E)构成了Arm设备内存类型的层次化约束体系:
- G(Gathering/汇聚):是否允许多次访问合并为一次事务。非汇聚(nG)保证每次访问都独立发送到端点。
- R(Reordering/重排序):是否允许访问在到达外设时改变顺序。非重排序(nR)保证访问按程序顺序到达外设。
- E(Early Write Acknowledgement/早期写确认):写确认是否必须来自最终端点(外设本身)而非中间缓冲。
三种属性组合从强到弱排列:Device-nGnRnE(最强,相当于ARMv7的Strongly-ordered)→ Device-nGnRE → Device-nGRE → Device-GRE(最弱,类似于Normal但禁止推测访问)。
Armv8设备内存类型如下:
| 内存类型 | 描述 |
|---|---|
| Device-nGnRnE | 设备非汇聚、非重排序、无早期写确认。等同于早期架构版本中的强排序(Strongly-ordered)内存类型。 |
| Device-nGnRE | 设备非汇聚、非重排序、有早期写确认。等同于早期架构版本中的设备(Device)内存类型。 |
| Device-nGRE | 设备非汇聚、可重排序、有早期写确认。Armv8将此内存类型添加到早期架构版本中的页表格式中。需要使用屏障来排序对Device-nGRE内存的访问。 |
| Device-GRE | 设备可汇聚、可重排序、有早期写确认。Armv8将此内存类型添加到早期架构版本中的页表格式中。Device-GRE内存具有最少的约束。其行为类似于Normal内存,但禁止对Device-GRE内存进行推测性访问。 |
这些统称为任意设备内存类型(any Device memory type)。按列表向下,内存类型被描述为越来越弱(weaker);相反,按列表向上,内存类型被描述为越来越强(stronger)。
Note(注意)
- 如类型列表所示,这些附加属性是层次化的。例如,允许汇聚的内存位置也必须允许重排序和早期写确认。
- 架构不要求实现区分这些内存类型中的每一种,Arm认识到并非所有实现都会这样做。描述每个属性的子节描述了该属性的实现规则。
所有这些内存类型具有以下属性:
译者注: 推测性访问(Speculative access)是处理器为了性能而提前执行的内存访问,即使程序控制流可能最终不需要该访问的结果。Normal内存允许推测性读取,而Device内存禁止推测性访问——这是一个关键区别。这是因为设备内存的读操作可能有副作用(如清除状态寄存器),推测性执行会导致意外的副作用或错误的状态读取。
- 推测性数据访问不允许用于具有任何设备内存属性的内存位置。这意味着对任何设备内存类型的每次内存访问必须是由程序的简单顺序执行所生成的访问。对此有以下例外:
- SIMD和浮点指令生成的读取可以访问指令未**显式访问(explicitly accessed)**的字节,前提是这些被访问的字节位于一个16字节窗口内(16字节对齐),且该窗口包含至少一个由指令显式访问的字节。
- 对于由SVE无谓词加载指令执行的读取(包括硬件推测),以下所有条件成立:
- 对于任何64字节对齐的64字节窗口,如果该窗口包含至少1个由指令显式访问的字节,则窗口中的任何字节都可能被该指令访问。
- 指令访问的所有字节将位于一个64字节对齐的64字节窗口内,该窗口包含至少1个由指令显式访问的字节。
- 对于由SVE谓词加载指令(非非时态加载)执行的读取(包括硬件推测),以下所有条件成立:
- 对于任何64字节对齐的64字节窗口,如果该窗口包含至少1个由指令的**活跃元素(Active element)**显式访问的字节,则窗口中的任何字节都可能被该指令访问。
- 指令访问的所有字节将位于一个64字节对齐的64字节窗口内,该窗口包含至少1个由指令的活跃元素显式访问的字节。
- 对于由SVE谓词非时态加载指令从具有汇聚属性的内存位置执行的读取(包括硬件推测),以下所有条件成立:
- 对于任何128字节对齐的128字节窗口,如果该窗口包含至少1个由指令的活跃元素显式访问的字节,则窗口中的任何字节都可能被该指令访问。
- 指令访问的所有字节位于一个128字节对齐的128字节窗口内,该窗口包含至少1个由指令的活跃元素显式访问的字节。
- 架构允许**内存拷贝和内存设置(Memory Copy and Memory Set)**CPY*指令对任何内存位置(即使标记为Device)进行推测性读取,但仅限于位于[Xs]到[Xs+Xn-1]范围内、64字节对齐的64字节量之内。
- 对于具有汇聚属性的设备内存,LDNP指令生成的读取允许访问指令未显式访问的字节,前提是被访问的字节位于一个128字节对齐的128字节窗口内,且该窗口包含至少一个由指令显式访问的字节。
- 如果加载或存储指令执行一系列内存访问(而非按照单次拷贝原子性规则定义的一次单次拷贝原子访问),这些访问可能因执行该加载或存储指令而多次发生。参见 单次拷贝原子访问的属性。
- 未通过指针认证检查并从设备内存中位置加载的LDRAA或LDRAB指令,如果满足访问该设备位置的所有其他要求,则允许对该位置执行一次读访问。
Note(注意)
- 如 Arm架构中的原子性 所述,生成一系列访问的指令可能因在该系列访问过程中发生异常而被放弃。从异常返回后,指令重新启动,因此一个或多个内存位置可能被多次访问。这可能导致对程序中只定义了一次访问的位置进行重复访问。因此,Arm强烈建议不要使用跨越转换粒度边界的单条指令访问设备内存,也不要以其他可能导致部分访问被中止的方式访问设备内存。
- 对所有内存类型,禁止对其他观察者可见的写推测(Write speculation)。
- 对具有任何设备内存类型的内存位置的显式内存写效果在有限时间内完成。
- 如果从具有设备内存类型的内存位置读取时返回的值在没有观察者的显式内存写效果的情况下发生变化,则该变化也必须在有限时间内被系统中所有观察者全局观察到。这种变化可能发生在保存状态信息的外设位置中。
- 对内存位置的数据访问对于系统中所有观察者是一致的,并相应地被视作外部可共享(Outer Shareable)。
- 具有任何设备内存属性的内存位置不能分配到缓存中。
- 对具有任何设备内存属性的内存位置的显式内存写效果必须在有限时间内到达该地址在内存系统中的端点。对同一位置的两次设备内存类型的显式内存写效果可能在到达端点之前被合并,除非两次显式内存写效果都具有非汇聚属性,或者两次显式内存写效果之间存在ordered-before关系。
- 对于对任何设备内存类型的访问,DMB指令在**实现定义(IMPLEMENTATION DEFINED)**大小的单个外设或内存块上的所有访问之间引入屏障有序优先关系。更多信息请参见 排序关系。
- 如果内存位置不支持非对齐内存访问,则对该内存位置的非对齐访问会在将该位置定义为Device的第一阶段翻译时产生对齐故障。
- 如果内存位置支持非对齐内存访问,且该内存位置被标记为Device,则对该内存位置的非对齐访问是否会在第一阶段翻译时产生对齐故障是**实现定义(IMPLEMENTATION DEFINED)**的。
- 硬件不会阻止从具有任何设备内存属性的内存位置进行推测性指令获取,除非该内存位置也被标记为所有异常级别的执行never(execute-never)。
Note(注意)
这意味着为了防止从具有设备内存属性的内存位置进行推测性指令获取,任何被分配了任何设备内存类型的位置也必须被标记为所有异常级别的执行never。未将具有任何设备内存属性的内存位置标记为所有异常级别的执行never是编程错误。
Note(注意)
在HCR_EL2.TGE == 1且HCR_EL2.DC == 0的系统中,在EL1&0转换机制下,由于所有位置都被视为Device而导致的任何对齐故障都是第一阶段翻译的故障。这导致ESR_EL2.ISS[24]为0。
另请参见 内存访问限制。
用于页表遍历(translation table walks)的内存类型不能在TCR_ELx中定义为任何设备内存类型。对于EL1&0转换机制,在阶段1页表遍历期间进行的内存访问受到阶段2转换的影响,由于第二阶段转换的结果,第一阶段页表遍历的访问可能被指向具有任何设备内存类型的内存位置。这些访问可能是推测性进行的。当HCR_EL2.PTW位的值为1时,如果第一阶段页表遍历访问任何设备内存类型,则会产生阶段2权限故障。
Note(注意)
通常,使页表遍历访问任何设备内存类型是编程错误。
对于从具有Device属性但未标记为当前异常级别执行never的内存位置进行指令获取,实现可以:
- 将该指令获取视为访问具有Normal不可缓存属性的内存位置。
- 产生权限故障。
B2.10.2.1 汇聚(Gathering)
在设备内存属性中:
| 标识 | 含义 |
|---|---|
| G | 表示该位置具有汇聚属性(Gathering attribute)。 |
| nG | 表示该位置不具有汇聚属性,即非汇聚(non-Gathering)。 |
汇聚属性决定是否允许以下任一种情况:
- 将同一类型的多次内存访问(读或写)到同一内存位置合并为单个事务。
- 将同一类型的多次内存访问(读或写)到不同内存位置合并为互联上的单个内存事务。
Note(注意)
这也适用于缓存的写回,无论是由于自然驱逐(Natural eviction)还是缓存维护指令的结果。
对于具有汇聚属性的内存类型,只要遵循内存位置的排序和一致性规则,上述两种行为都是允许的。
对于具有非汇聚属性的内存类型,上述两种行为都不允许。因此:
- 进行的内存访问次数对应于程序的简单顺序执行所生成的次数。
译者注: 单次拷贝原子性(Single-copy atomicity)是Arm内存模型的核心概念之一。一次单次拷贝原子访问的效果对系统中所有观察者同时可见——要么所有观察者都看到完整结果,要么都没有看到。多寄存器加载/存储指令(如LDP/STP)通常生成多次单次拷贝原子访问,每次对应一个寄存器。nG(非汇聚)属性要求每次访问必须作为独立单次拷贝原子事务到达端点,不得合并。
- 所有访问以其单次拷贝原子大小发生,除了不要求PE之外的内存系统能够识别生成多次单次拷贝原子访问的多寄存器加载/存储指令所访问的单次拷贝原子大小。参见 访问设备内存的多寄存器加载和存储。
在两次访问之间(其中一次访问屏障有序优先于另一次访问)的汇聚是不允许的。
由内存拷贝和内存设置指令生成的内存访问之间的汇聚始终允许。
从具有非汇聚属性的内存位置进行的读取不能来自缓存或缓冲区,而必须来自该地址在内存系统中的端点。通常是外设或物理内存。
Note(注意)
- 从具有汇聚属性的内存位置进行的读取可以来自先前写入的中间缓冲,前提是:
- 这些访问之间没有影响两者的DMB或DSB屏障。
- 这些访问之间没有其他要求访问有序的排序构造。这种构造可能是Load-Acquire和Store-Release的组合。
- 这些访问不是由Store-Release指令生成的。
- Arm架构仅定义程序员可见的行为。因此,如果程序员无法判断是否发生了汇聚,就可以执行汇聚。
允许实现以符合非汇聚属性所指定要求的方式执行具有汇聚属性的访问。
不允许实现以符合汇聚属性所允许的宽松方式执行具有非汇聚属性的访问。
B2.10.2.2 重排序(Reordering)
在设备内存属性中:
| 标识 | 含义 |
|---|---|
| R | 表示该位置具有重排序属性(Reordering attribute)。对该位置的访问可以在适用于Normal不可缓存内存的相同规则内进行重排序。所有具有重排序属性的内存类型具有与对Normal不可缓存内存访问相同的排序规则,参见 排序关系。 |
| nR | 表示该位置不具有重排序属性,即非重排序(non-Reordering)。 |
Note(注意)
某些互联结构(如PCIe)执行非常有限的重排序,这对软件使用并不重要。禁止将非重排序内存类型与这些互联一起使用超出了Arm架构的范围。
对于所有具有非重排序属性的内存类型,到达**实现定义(IMPLEMENTATION DEFINED)**大小的单个外设(由外设定义)的内存访问顺序必须与程序的简单顺序执行中出现的顺序相同。即,访问按程序顺序出现。此排序适用于使用任何具有非重排序属性的内存类型的所有访问。因此,如果对同一外设有Device-nGnRE和Device-nGnRnE的混合访问,这些访问按程序顺序发生。如果内存访问不是指向外设,则该属性不施加任何限制。
Note(注意)
- 单个外设的实现定义大小与DMB指令提供的排序保证所适用的尺寸相同。
- Arm架构仅定义程序员可见的行为。因此,如果程序员无法判断是否发生了重排序,就可以进行重排序。
- 架构仅要求非重排序属性适用于访问到达单个实现定义大小的内存映射外设时的顺序,并不要求对SDRAM的内存访问的观察顺序产生影响。因此,作为内存模型正式定义一部分的 排序关系 中描述的不同位置之间的排序关系不受非重排序属性的影响。它确实会影响 外设到达顺序(Peripheral arrival order) 中描述的外设到达顺序。
- 如果同一内存位置使用不同的别名映射,且具有不同的属性值,则属于不匹配属性的类型。不同的属性可能是:
- 不同的重排序属性值。
- 不同的设备内存属性值。
- 当实现FEAT_XS时,不同的XS属性值。
关于访问具有不匹配属性的内存的效果,参见 不匹配的内存属性。
实现:
- 允许以符合非重排序属性所指定要求的方式执行具有重排序属性的访问。
- 不允许以符合重排序属性所允许的宽松方式执行具有非重排序属性的访问。
非重排序属性在以下情况之间不要求任何超出适用于Normal内存的额外排序:
- 对具有非重排序属性的一个物理地址的访问与对具有重排序属性的不同物理地址的访问之间。
- 对具有非重排序属性的一个物理地址的访问与对Normal内存的不同物理地址的访问之间。
- 具有非重排序属性的访问与对不同实现定义大小的外设的访问之间。
非重排序属性对缓存维护指令的排序没有影响,即使指令中指定的内存位置具有非重排序属性。
非重排序属性对由内存拷贝和内存设置指令引起的内存访问没有影响。
B2.10.2.3 早期写确认(Early Write Acknowledgement)
在设备内存属性中:
| 标识 | 含义 |
|---|---|
| E | 表示该位置具有早期写确认属性(Early Write Acknowledgement attribute)。 |
| nE | 表示该位置具有无早期写确认属性(No Early Write Acknowledgement attribute)。 |
如果为设备内存位置分配了无早期写确认属性:
- 对于PE所在系统架构要求写确认来自端点的内存系统端点,保证:
- 只有写访问的端点返回写访问确认。
- 内存系统中没有更早的点返回写确认。
- 对于PE所在系统架构不要求写确认来自端点的内存系统端点,不要求写确认来自端点。
Note(注意)
对于分配了无早期写确认属性的设备内存位置的写入,在任何等效写入同一位置但没有分配无早期写确认属性时不产生中止的情况下,预期不会产生中止。
这意味着,执行对该无早期写确认位置写入的PE所执行的DSB屏障指令,仅在写入已到达其内存系统中的端点后才完成(如果系统架构要求如此)。
外设是需要写确认来自端点的系统端点的示例。
Note(注意)
- 早期写确认属性仅影响端点确认的返回位置,不影响访问之间的端点到达顺序,后者由设备重排序属性或使用屏障创建顺序决定。
- 需要端点写确认的物理内存映射区域超出了Arm架构定义的范围,必须作为PE所在系统架构的一部分进行定义。特别是,作为PCIe配置写入处理的内存区域预期支持端点写确认。
- Arm认识到并非物理内存映射的所有区域都能支持端点写确认。特别是,Arm预期作为PCIe下发布写(posted writes)处理的内存区域不支持端点写确认。
- 为获得最大的软件兼容性,Arm强烈建议,标准软件驱动程序期望使用DSB指令确定写入已到达其端点的所有外设,都放置在支持端点写确认的物理内存映射区域中。
B2.10.2.4 访问设备内存的多寄存器加载和存储(Multi-register loads and stores that access Device memory)
对于所有加载或存储多个通用寄存器并为该加载或存储生成多次单次拷贝原子访问的指令,不要求PE之外的内存系统能够识别这些加载或存储指令所访问的单次拷贝原子大小。
对于所有加载或存储多个通用寄存器的指令,寄存器被访问的顺序不由架构定义。这甚至适用于对任何类型设备内存的访问。
对于所有加载或存储一个或多个Advanced SIMD&FP或SVE寄存器并为该加载或存储生成多次单次拷贝原子访问的指令,不要求PE之外的内存系统能够识别这些加载或存储指令所访问的单次拷贝原子大小,即使是对任何类型设备内存的访问。
架构允许加载或存储多个通用寄存器或SIMD和浮点寄存器的指令的非推测性执行可能导致对同一地址的重复访问,即使结果访问指向任何类型的设备内存。
B2.10.2.5 访问设备内存的SVE加载和存储(SVE loads and stores that access Device memory)
RXLLJZ 适用于Advanced SIMD和浮点加载/存储指令的设备内存访问的所有规则也适用于SVE加载/存储指令的设备内存访问。
IYHWJT 额外的规则适用于SVE加载/存储指令的设备内存访问。
RNYMWH 当执行SVE向量预取指令时,任何由此产生的读取内存保证不会访问设备内存。
RSBHLD 当执行SVE无故障(Non-fault)向量加载时,或者当来自首次故障(First-fault)加载的任何元素(首个活跃元素除外)尝试访问设备内存时,由此产生的读取内存将不会访问设备内存。
RTMVNR 当执行SVE无故障向量加载指令时,任何活跃元素对设备内存的访问尝试被抑制并在FFR中报告。
RSFBKQ 当执行SVE首次故障向量加载指令时,为首个活跃元素执行的任何读取内存可以访问设备内存。
RBHNQN 当执行SVE首次故障向量加载指令时,除首个活跃元素外的任何活跃元素对设备内存的访问尝试被抑制并在FFR中报告。
RQBLMZ SVE加载或存储指令对设备内存的任何访问都被宽松处理,可能表现为:
- 内存具有汇聚属性(Gathering attribute),无论nG属性的配置值如何。
- 内存具有重排序属性(Reordering attribute),无论nR属性的配置值如何。
- 内存具有早期确认属性(Early Acknowledgment attribute),无论nE属性的配置值如何。
属性是否被归类为不匹配严格由从页表项派生的内存属性决定。
B2.10.2.6 访问设备内存的流式SVE模式加载和存储(Streaming SVE mode loads and stores that access Device memory)
RXHFBX 当PE处于流式SVE模式(Streaming SVE mode)且FEAT_SME_FA64未实现或未在当前异常级别启用时,Advanced SIMD&FP加载/存储指令对设备内存的任何访问都被宽松处理,可能表现为:
- 汇聚属性为1,无论nG属性的配置值如何。
- 重排序属性为1,无论nR属性的配置值如何。
- 早期确认属性为1,无论nE属性的配置值如何。
属性是否被归类为不匹配严格由从页表项派生的内存属性决定。
另请参见:
- 流式SVE模式(Streaming SVE mode)
B2.10.3 内存访问限制(Memory access restrictions)
以下限制适用于内存访问:
对于由同一条指令生成的对内存中任意两个相邻字节p和p+1的两次显式内存读效果,以及由同一条指令生成的对内存中任意两个相邻字节p和p+1的两次显式内存写效果:
- 字节p和p+1必须具有相同的内存类型和可共享性属性,否则结果是受限不可预测(CONSTRAINED UNPREDICTABLE)。例如,跨越Normal内存和Device内存之间边界的LD1、ST1或非对齐加载/存储是受限不可预测的。
- 除了缓存分配提示可能存在的差异外,Arm不推荐为字节p和p+1设置不同的可缓存性属性。
关于允许的受限不可预测行为,参见 跨越具有不同内存类型或可共享性属性的页边界。
如果导致多次访问任何类型设备内存的指令的访问跨越与最小实现转换粒度对应的地址边界,则行为是受限不可预测(CONSTRAINED UNPREDICTABLE),跨越设备访问的外设边界 描述了允许的行为。因此,重要的是,对易失性内存设备的访问不应使用跨越最小实现转换粒度大小的地址边界的单条指令进行。
Note(注意)
- 所涉及的边界是指两个设备内存区域之间的边界,这两个区域的大小均为最小实现转换粒度的大小,并与最小实现转换粒度的大小对齐。
- 此限制意味着,重要的是,对易失性内存设备的访问不应使用跨越最小实现转换粒度大小的地址边界的单条指令进行。
- Arm期望此限制约束易失性内存设备在系统内存映射中的放置,而非期望编译器了解内存访问的对齐方式。
B2.11 不匹配的内存属性(Mismatched memory attributes)
译者注: 用户要求以”B2.11 转换后备缓冲器(TLB)”为标题开头,但本节原文实际内容为”B2.11 Mismatched memory attributes”(不匹配的内存属性),TLB相关内容位于手册其他章节。此处按原文实际内容翻译。
B2.11 不匹配的内存属性
内存属性由特权软件控制。更多信息,请参见《AArch64虚拟内存系统架构》。
如果对一个物理内存位置的所有访问并非都使用该位置以下所有属性的统一定义,则称该物理内存位置以**不匹配的属性(mismatched attributes)**被访问:
- 内存类型(Memory type):Device-nGnRnE、Device-nGnRE、Device-nGRE、Device-GRE 或 Normal。
- 共享性(Shareability)。
- 可缓存性(Cacheability),针对同一级内部(inner)或外部(outer)缓存,但不包括任何缓存分配提示(cache allocation hints)。
- 当实现FEAT_XS时,XS属性。
这些属性统称为内存属性(memory attributes)。
如果实现了FEAT_MTE2,那么对某个位置的访问使用了内存属性的统一定义,但该位置的Tagged(标记)属性不同,不会导致不匹配访问的发生。
如果实现了FEAT_MTE_PERM,则NoTagAccess(无标签访问)属性不参与不匹配属性的判定。
注: 在本文件中,术语”位置(location)”和”内存位置(memory location)”指当前一致性粒度(coherency granule)内的任何字节,两者可互换使用。
当以不匹配的属性访问一个内存位置时,唯一可能对软件可见的影响包括以下一项或多项:
- 单处理器(Uniprocessor)语义可能丢失,即:
- 一个代理(agent)对该内存位置的读取可能不会返回同一代理最近写入该位置的值。
- 同一代理使用不同内存属性对该内存位置的多次写入可能不会按程序顺序执行。
- 当多个代理试图访问一个内存位置时,可能会丢失一致性(coherency)。
- 可能丢失从内存类型派生而来的属性,如本节后续条目所述。
- 如果所有线程中用于访问给定内存位置的全部Load-Exclusive/Store-Exclusive指令未使用一致的内存属性,则独占监视器(Exclusives monitor)状态变为UNKNOWN(未知)。
- 在同一个Write-Back(回写)粒度内,以非Write-Back可缓存属性写入的字节,与以Write-Back可缓存属性写入的字节并存时,其值可能因缓存回写而恢复为旧值。
与不匹配内存类型属性相关的属性丢失,仅指Device内存相对于Normal内存所额外具有的以下属性:
- 禁止推测性读访问(Prohibition of Speculative read accesses)。
- 禁止合并(Prohibition on Gathering)。
- 禁止重排序(Prohibition on reordering)。
在以下情况下,当以不匹配的属性访问一个物理内存位置时,适用一组更为严格的行为。每种情况的说明也描述了适用的行为:
任何代理使用相同的Memory type(内存类型)、Shareability(共享性)和Cacheability(可缓存性)属性的统一定义来读取该内存位置时,仅当满足以下所有条件时,才能保证以该统一定义所需的一致性程度进行一致性访问:
- 所有的写入操作都针对该内存位置的一个**别名(alias)**执行,该别名使用相同的Memory type、Shareability和Cacheability属性的定义。
- 并且满足以下二者之一:
- 所有的写入操作都针对该内存位置的一个别名执行,该别名的Inner Cacheability和Outer Cacheability属性均为Non-cacheable(不可缓存)。
- 该内存位置的所有别名都使用一个Shareability属性的定义,该定义涵盖了所有有权访问该位置的代理。
如果所有不匹配的属性都将该内存位置定义为以下之一,则由不匹配属性引起的可能的软件可见影响将被更精确定义:
- 任意Device内存类型。
- Inner Non-cacheable(内部不可缓存)、Outer Non-cacheable(外部不可缓存)的Normal内存。
在这些情况下,不匹配属性唯一允许的软件可见影响是以下一项或多项: - 当多个代理试图访问该内存位置时,可能丢失从内存类型派生而来的属性。
- 对同一内存位置使用不同内存属性的内存事务可能发生重排序,可能导致一致性或单处理器语义的丢失。任何可能的一致性丢失或单处理器语义丢失都可以通过在访问同一内存位置(可能使用不同属性)的访问之间插入DMB屏障指令来避免。
在单处理器语义、顺序或一致性可能丢失的情况下,可以采用以下方法:
如果某内存位置的不匹配属性都赋予该位置相同的共享性属性且该位置具有可缓存属性,则可以通过使用软件缓存管理来避免共享性域内的单处理器语义、顺序或一致性的任何丢失。为此,软件必须使用在不同共享性域中的代理之间进行可缓存位置的顺序或一致性的软件管理所需的技术。这意味着:
- 在向一个不使用Write-Back属性的可缓存位置写入之前,如果有任何代理可能已经使用Write-Back属性向该位置进行了写入,软件必须从缓存中**无效化(invalidate)或清理(clean)**该位置。这可以避免用脏数据覆盖该位置。
- 在使用Write-Back属性向可缓存位置写入之后,软件必须从缓存中**清理(clean)**该位置,以使写入对外部内存可见。
- 在使用可缓存属性读取该位置之前,软件必须从缓存中无效化(invalidate),或**清理并无效化(clean and invalidate)**该位置,以确保缓存中保存的任何值反映外部内存中最后可见的值。
- 在对同一可缓存位置使用不同属性进行访问之间,执行DMB屏障指令。
在所有情况下:
- **位置(Location)**指当前一致性粒度内的任何字节。
- 可以使用清理并无效化指令(clean and invalidate instruction)代替清理指令(clean instruction),或代替无效化指令(invalidate instruction)。
- 在本节概述的序列中,所有缓存维护指令和内存事务都必须完成,或通过使用屏障操作进行排序(如果它们不能通过使用公共地址自然排序的话),参见《数据和指令缓存指令的顺序与完成(Ordering and completion of data and instruction cache instructions)》。
注: 在软件管理一致性的情况下,竞争条件(race condition)可能导致数据丢失。当不同的代理同时写入同一位置内的字节,并且一个代理的”无效化、写入、清理”序列与另一代理的等价序列重叠时,就会发生竞争条件。如果两个序列中的第一个操作是清理(clean)而非无效化(invalidate),也会发生竞争条件。
如果某位置的不匹配属性意味着对该位置可能存在具有不同共享性属性的多次可缓存访问,则仅当满足以下条件时,才能保证单处理器语义、顺序和一致性:
- 在PE上运行的软件在对该位置进行每次读取或写入之前和之后,从缓存中**清理并无效化(cleans and invalidates)**该位置。
- 在对同一内存位置使用不同属性的任何访问之间放置一个DMB屏障。
注: 本列表规则1中关于可能的竞争条件的注释也适用于本规则。
此外,如果多个代理试图使用Load-Exclusive或Store-Exclusive指令访问某个位置,且不同代理的访问与该位置相关联的不同内存属性,则独占监视器(Exclusives monitor)状态变为UNKNOWN(未知)。
Arm强烈建议软件不要对同一位置的别名使用不匹配的属性。具体实现可能不会优化使用不匹配别名的系统的性能。
注: 如《不可缓存访问与指令缓存(Non-cacheable accesses and instruction caches)》中所述,尽管不可缓存访问不允许被缓存在统一缓存(unified cache)中,但允许被缓存在指令缓存(instruction cache)中。尽管如此,当可执行内存同时存在可缓存和不可缓存别名时,这些别名必须被视为不匹配别名,以避免来自数据缓存或统一缓存(这些缓存可能持有将被引入指令缓存的条目)的一致性问题。
B2.12 同步与信号量(Synchronization and semaphores)

B2.12 同步与信号量(Synchronization and semaphores)
Armv8 提供了基于同步原语(synchronization primitives)的共享内存非阻塞同步机制。本节中关于同步原语的内存访问信息,适用于对 Normal 内存以及任何类型 Device 内存的访问。
注:
Armv8 同步原语的使用可扩展至多处理系统设计。
表 B2-2 显示了同步原语及相关的 CLREX 指令。
表 B2-2 同步原语及关联指令,A64 指令集
| 事务大小 | 额外语义 | 独占加载(Load-Exclusive)^a^ | 独占存储(Store-Exclusive)^a^ | 其他(Other)^a^ |
|---|---|---|---|---|
| 字节(Byte) | - | LDXRB | STXRB | - |
| 加载获取/存储释放(Load-Acquire/Store-Release) | LDAXRB | STLXRB | - | |
| 半字(Halfword) | - | LDXRH | STXRH | - |
| 加载获取/存储释放(Load-Acquire/Store-Release) | LDAXRH | STLXRH | - | |
| 寄存器(Register)^b^ | - | LDXR | STXR | - |
| 加载获取/存储释放(Load-Acquire/Store-Release) | LDAXR | STLXR | - | |
| 寄存器对(Pair)^b^ | - | LDXP | STXP | - |
| 加载获取/存储释放(Load-Acquire/Store-Release) | LDAXP | STLXP | - | |
| 无(None) | 清除独占(Clear-Exclusive) | - | - | CLREX |
^a^ A64 指令集中的指令。
^b^ 如果访问 X 寄存器,则寄存器指令操作于双字(doubleword);如果访问 W 寄存器,则操作于字(word)。如果访问 X 寄存器,则寄存器对指令操作于两个双字;如果访问 W 寄存器,则操作于两个字。
除了显示 CLREX 指令的那一行外,同一行中的两条指令构成一个独占加载/独占存储(Load-Exclusive/Store-Exclusive)指令对。对于访问非异常(non-aborting)内存地址 x 的独占加载/独占存储指令对,其使用模型如下:
- 独占加载(Load-Exclusive)指令从内存地址 x 读取一个值。
- 相应的独占存储(Store-Exclusive)指令仅在没有其他观察者(observer)、进程或线程对地址 x 执行过更近期的存储时,才成功写回内存地址 x。独占存储指令返回一个状态位,用于指示该写内存操作是否成功。
独占加载指令会标记一小块内存区域用于独占访问。该标记块的大小是由实现定义(IMPLEMENTATION DEFINED) 的,参见”标记与标记内存块的大小(Marking and the size of the marked memory block)”。对标记块中任一地址执行的独占存储指令会清除该标记。
注:
在本节中,术语 PE 包含任何能够生成独占加载或独占存储指令的观察者。
以下各节提供更多信息:
- 独占访问指令与不可共享(Non-shareable)内存位置。
- 独占访问指令与可共享(Shareable)内存位置。
- 标记与标记内存块的大小(Marking and the size of the marked memory block)。
- 上下文切换支持(Context switch support)。
- 独占加载与独占存储指令的使用限制(Load-Exclusive and Store-Exclusive instruction usage restrictions)。
- 自旋锁中 WFE 和 SEV 指令的使用(Use of WFE and SEV instructions by spin-locks)。
B2.12.1 独占访问指令与不可共享内存位置(Exclusive access instructions and Non-shareable memory locations)
对于可共享性属性(shareability attribute)为不可共享(Non-shareable)的内存位置,独占访问指令依赖于一个本地的独占监视器(local Exclusives monitor,或称 local monitor),该监视器标记由 PE 执行的任何独占加载指令所生成的显式内存读取效应(Explicit Memory Read effect)的地址。
独占加载指令执行一次从内存的加载,并且:
- 执行该指令的 PE 标记该物理内存地址用于独占访问。
- 执行该指令的 PE 的本地监视器(local monitor)转换到独占访问状态(Exclusive Access state)。
独占存储指令执行一次条件存储到内存,其结果取决于本地监视器的状态:
如果本地监视器处于独占访问状态(Exclusive Access state)
- 如果该独占存储指令的显式内存写效应(Explicit Memory Write effect)的地址与之前执行独占加载指令时在监视器中标记的地址相同,则执行存储。否则,存储是否执行是由实现定义(IMPLEMENTATION DEFINED) 的。
- 状态值被返回到一个寄存器:
- 如果存储发生,状态值为 0。
- 否则,状态值为 1。
- 执行该指令的 PE 的本地监视器转换到开放访问状态(Open Access state)。
当独占监视器处于独占访问状态时,称该监视器被设置(set)。
如果本地监视器处于开放访问状态(Open Access state)
- 不执行存储。
- 状态值 1 被返回到一个寄存器。
- 本地监视器保持开放访问状态不变。
当独占监视器处于开放访问状态时,称该监视器被清除(clear)。
独占存储指令定义了返回状态值的寄存器。
当 PE 使用除独占存储指令以外的任何指令执行写入时:
- 如果写入的目标 PA 未被其本地监视器标记为独占访问,且该本地监视器处于独占访问状态,则该写入是否影响本地监视器的状态是由实现定义(IMPLEMENTATION DEFINED) 的。
- 如果写入的目标 PA 已被其本地监视器标记为独占访问,则该写入是否影响本地监视器的状态是由实现定义(IMPLEMENTATION DEFINED) 的。
如果对已标记 PA 的存储是由引起该 PA 被标记的观察者之外的其他观察者执行的,则该存储是否会导致本地监视器中的标记被清除,是由实现定义(IMPLEMENTATION DEFINED) 的。
图 B2-4 显示了本地监视器的状态机以及图中所示各操作的效果。
图 B2-4 本地监视器状态机图(Local monitor state machine diagram)
译者注: 原文中的状态机图在此处无法以文本形式完整再现。该图描述了本地监视器在以下几个事件间的状态转换:复位(Reset)、独占加载(Load Exclusive)、独占存储(Store Exclusive,又分为地址匹配和不匹配两种情况)、以及来自其他观察者的存储(Store from another observer)。状态在”独占访问(Exclusive Access)”和”开放访问(Open Access)”之间转换。详细的状态转换逻辑见上文文字描述。
关于标记的更多信息,请参见”标记与标记内存块的大小(Marking and the size of the marked memory block)”。
注:
对于如图 B2-4 所示的本地监视器状态机:
- 本地监视器的由实现定义(IMPLEMENTATION DEFINED) 选项与本地监视器的构造方式一致,即它不持有任何 PA,而是将任何访问视为与先前独占加载指令的地址相匹配。
- 本地监视器的实现可以不知道来自其他 PE 的独占加载和独占存储指令。
- 架构不要求由其他 PE 执行的、非独占加载指令的加载指令对本地监视器产生任何影响。
- 当存储或独占存储(StoreExcl)来自其他观察者时,从独占访问状态到开放访问状态的转换是否发生,是由实现定义(IMPLEMENTATION DEFINED) 的。
B2.12.1.1 由推测执行导致的本地监视器状态变化(Changes to the local monitor state resulting from speculative execution)
架构允许本地监视器由于推测(speculation)或其他原因转换到开放访问状态。这是对图 B2-4 中由架构执行操作所导致的开放访问状态转换的补充。
实现必须确保:
- 本地监视器除了由图 B2-4 所示操作的架构执行(architectural execution)所导致之外,不可被观察到转换到独占访问状态。
- 任何非由图 B2-4 所示操作的架构执行所导致的本地监视器到开放访问状态的转换,不得无限期地延迟执行的前进进度(forward progress)。
B2.12.2 独占访问指令与可共享内存位置(Exclusive access instructions and Shareable memory locations)
在本节的语境中,可共享内存位置(shareable memory location)是指具有(或被视为具有)内部可共享(Inner Shareable)或外部可共享(Outer Shareable)可共享性属性的内存位置。
对于可共享内存位置,独占访问指令依赖于:
- 系统中每个 PE 的本地监视器(local monitor),用于标记该 PE 执行独占加载的任何地址。本地监视器的运行方式如”独占访问指令与不可共享内存位置(Exclusive access instructions and Non-shareable memory locations)”所述,但区别在于:对于可共享内存,任何独占存储随后都要接受全局监视器(global monitor)的检查(如果在该节中描述为至少执行以下操作之一):
- 更新内存(Updating memory)。
- 返回状态值 0(Returning a status value of 0)。
本地监视器可以忽略系统中其他 PE 的访问。
- 全局监视器(global monitor),用于将 PA 标记为特定 PE 的独占访问。该标记稍后用于确定一个未被本地监视器拒绝的独占存储是否能够实际发生。在内存位置的可共享域(shareability domain)中,任何其他观察者对该标记块的任何成功写入,都保证会清除该标记。对于系统中的每个 PE,全局监视器:
- 可以持有至少一个标记块。
- 为其可持有的每个标记块维护一个状态机。
注:
对于每个 PE,架构只要求全局监视器支持单个标记地址。任何可能受益于在单个 PE 上使用多个标记地址的情况都是不可预测(UNPREDICTABLE) 或受约束的不可预测(CONSTRAINED UNPREDICTABLE) 的,请参见”独占加载与独占存储指令的使用限制(Load-Exclusive and Store-Exclusive instruction usage restrictions)”。
注:
全局监视器既可以驻留在 PE 内部,也可以作为内存接口处的二级监视器存在。监视器的由实现定义(IMPLEMENTATION DEFINED) 方面意味着全局监视器和本地监视器可以合并为一个单元,前提是该单元能执行本手册中定义的全局监视器和本地监视器功能。
对于可共享内存位置,在某些实现中以及对于某些内存类型,全局监视器的属性要求 PE 之外的功能支持。某些系统实现可能不会对所有内存位置实现此功能。特别是,这可能适用于:
- 系统实现中不支持硬件缓存一致性(hardware cache coherency)的任何内存类型。
- 在支持硬件缓存一致性的实现中,不可缓存(Non-cacheable)的内存,或被视为不可缓存的内存。
在此类系统中,由系统定义:
- 全局监视器是否被实现。
- 如果全局监视器被实现,它监视哪些地址范围或内存类型。
如果实现了 FEAT_MTE2,则对分配标签(Allocation Tags)的显式访问是否由全局监视器监视,是由实现定义(IMPLEMENTATION DEFINED) 的。更多信息请参见”内存标记扩展(The Memory Tagging Extension)”。
注:
为了在地址转换禁用时支持独占加载/独占存储机制的使用,系统可以在系统内存映射中定义至少一个内存位置(大小至少为转换粒度),以支持公共内部可共享域(common Inner Shareable domain)内所有 Arm PE 的全局监视器。然而,这不是架构要求。因此,需要互斥(mutual exclusion)的符合架构的软件不得依赖独占加载/独占存储机制,而必须使用软件算法(如 Lamport 面包店算法(Lamport’s Bakery algorithm))来实现互斥。
由于实现可以选择哪些内存类型被视为不可缓存(Non-cacheable),架构保证实现了全局独占监视器的唯一内存类型是:
- 内部可共享(Inner Shareable)、内部写回(Inner Write-Back)、外部写回(Outer Write-Back)Normal 内存。
- 外部可共享(Outer Shareable)、内部写回(Inner Write-Back)、外部写回(Outer Write-Back)Normal 内存。
架构只要求以此方式映射的常规内存(Conventional memory)支持此功能。
如果某个地址范围或内存类型未实现全局监视器,则对该位置执行独占加载或独占存储指令会产生以下一种或多种效果:
- 该指令生成一个外部中止(External abort)。
- 该指令生成一个由实现定义(IMPLEMENTATION DEFINED) 的 MMU 故障。该故障使用 ESR_ELx.DFSC = 110101 的数据中止故障状态码(Data Abort Fault status code)报告。
如果为 EL1&0 转换机制生成了由实现定义的 MMU 故障,则:- 如果该故障是由于第一阶段转换中定义的内存类型引起的,或者第二阶段转换被禁用,则这是第一阶段故障,异常被路由到 EL1。
- 否则,该故障是第二阶段故障,异常被路由到 EL2。
该故障的优先级是由实现定义(IMPLEMENTATION DEFINED) 的。
- 该指令被视为 NOP(无操作)。
- 独占加载指令被视为访问不可共享(Non-shareable)位置,但本地监视器的状态变为未知(UNKNOWN)。
- 独占存储指令被视为访问不可共享(Non-shareable)位置,但本地监视器的状态变为未知(UNKNOWN)。在这种情况下,如果独占存储指令是一个存储两个 64 位值的独占存储对指令,则所存储的两个值可能不会被原子性地(atomically)存储。
- 独占存储指令的结果寄存器中保存的值变为未知(UNKNOWN)。
此外,对于由非 PE 观察者(不实现独占访问或其他原子访问机制)生成的写事务,写入对 Arm PE 使用的全局和本地监视器产生的影响是由实现定义(IMPLEMENTATION DEFINED) 的。对于以下情况,这些写入可能不会清除其他 PE 的全局监视器:
- 某些地址范围。
- 某些内存类型。
B2.12.2.1 全局独占监视器的操作(Operation of the global Exclusives monitor)
来自可共享内存的独占加载指令执行一次从内存的加载,并使该访问的 PA 被标记为请求 PE 的独占访问。该访问也可能导致从请求 PE 已标记的任何其他 PA 上移除独占访问标记。
注:
全局监视器每个 PE 只支持一个未完成的(outstanding)对可共享内存的独占访问。
一个 PE 执行的独占加载指令对任何其他 PE 的全局监视器状态没有影响。
独占存储指令执行一次条件存储到内存:
- 仅当被访问的 PA 被标记为请求 PE 的独占访问,并且请求 PE 的本地监视器和全局监视器状态机都处于独占访问状态时,该存储才保证成功。在这种情况下:
- 状态值 0 被返回到一个寄存器,以确认存储成功。
- 请求 PE 的全局监视器状态机的最终状态是由实现定义(IMPLEMENTATION DEFINED) 的。
- 如果被访问的地址在任何其他 PE 的全局监视器状态机中被标记为独占访问,则该状态机转换到开放访问状态。
- 如果没有地址被标记为请求 PE 的独占访问,则存储不成功:
- 状态值 1 被返回到一个寄存器,以指示存储失败。
- 全局监视器不受影响,并为该请求 PE 保持开放访问状态。
- 如果不同的 PA 被标记为请求 PE 的独占访问,则存储是否成功是由实现定义(IMPLEMENTATION DEFINED) 的:
- 如果存储成功,状态值 0 被返回到一个寄存器;否则返回值 1。
- 如果该 PE 的全局监视器状态机在独占存储指令之前处于独占访问状态,则该状态机是否转换到开放访问状态是由实现定义(IMPLEMENTATION DEFINED) 的。
独占存储指令定义了返回状态值的寄存器。
在共享内存系统中,全局监视器为系统中的每个 PE 实现一个独立的状态机。用于 PE(n) 对可共享内存访问的状态机可以响应其可见的所有可共享内存访问。这意味着它响应:
- 由 PE(n) 生成的访问。
- 由内存位置可共享域中其他观察者生成的访问。这些访问被标识为 (!n)。
在共享内存系统中,全局监视器为系统中每个可以生成独占加载或独占存储指令的观察者实现一个独立的状态机。
全局监视器:
- 处于独占访问状态时,称为被设置(set)。
- 处于开放访问状态时,称为被清除(clear)。
B2.12.2.1.1 清除全局监视器事件(Clear global monitor event)
每当 PE 的全局监视器状态从独占访问变为开放访问时,会生成一个事件(event)并保存在该 PE 的事件寄存器(Event register)中。该寄存器由等待事件机制(Wait for Event mechanism)使用,请参见”进入低功耗状态的机制(Mechanisms for entering a low-power state)”。
图 B2-5 显示了多处理器系统中全局监视器中 PE(n) 的状态机。
图 B2-5 多处理器系统中 PE(n) 的全局监视器状态机图(Global monitor state machine diagram for PE(n) in a multiprocessor system)
译者注: 原文中的状态机图在此处无法以文本形式完整再现。该图描述了全局监视器在以下事件间的状态转换:PE(n) 执行独占加载(Load Exclusive by n)、其他观察者(!n)对标记地址的存储(Store by !n to marked address)、其他观察者(!n)对标记地址的独占存储(Store Exclusive by !n to marked address)、以及可能的清除独占指令(CLREX)。状态在”独占访问(Exclusive Access)”和”开放访问(Open Access)”之间转换。
关于标记的更多信息,请参见”标记与标记内存块的大小(Marking and the size of the marked memory block)”。
注:
对于如图 B2-5 所示的全局监视器状态机:
- 架构不要求由其他 PE 执行的、非独占加载指令的加载指令对全局监视器产生任何影响。
- 独占存储指令是否成功更新内存,取决于被访问的地址是否与发出该独占存储指令的 PE 的标记可共享内存地址匹配,以及本地和全局监视器是否处于独占状态。因此,图 B2-5 仅显示了 (!n) 的操作如何引起 PE(n) 状态机的状态转换。
- 独占加载指令只能更新发出该独占加载指令的 PE 的标记可共享内存地址。
- 当全局监视器处于独占访问状态时,CLREX 指令是否导致全局监视器从独占访问状态转换到开放访问状态,是由实现定义(IMPLEMENTATION DEFINED) 的。
- 以下情况是由实现定义(IMPLEMENTATION DEFINED) 的:
- 对不可共享(Non-shareable)内存位置的修改是否会导致全局监视器从独占访问状态转换到开放访问状态。
- 对不可共享(Non-shareable)内存位置的独占加载指令是否会导致全局监视器从开放访问状态转换到独占访问状态。
B2.12.3 标记与标记内存块的大小(Marking and the size of the marked memory block)
当执行独占加载指令时,所生成的标记块会忽略 64 位内存地址的最低有效位(least significant bits)。
当执行独占加载指令时,通过忽略内存地址的最低有效位,会创建一个大小为 2^a^ 字节的标记块。标记地址(marked address)是该标记块内的任何地址。标记内存块的大小称为独占预留粒度(Exclusives reservation granule)。独占预留粒度是由实现定义(IMPLEMENTATION DEFINED) 的,范围为 4-512 个字(words)。
注:
这一定义意味着独占预留粒度为:
- 在 a 为 4 的实现中为 4 个字。
- 在 a 为 11 的实现中为 512 个字。
例如,在 a 为 4 的实现中,对地址 0x341B4 的成功 LDXRB 使用地址的 bits[47:4] 定义一个标记块。这意味着从 0x341B0 到 0x341BF 的四个字的内存被标记为独占访问。
在某些实现中,CTR 标识了独占预留粒度,请参见 CTR_EL0。否则,软件必须假定实现了最大的独占预留粒度,即 512 个字。
B2.12.4 上下文切换支持(Context switch support)
异常返回(exception return)会清除本地监视器。因此,在大多数情况下,作为上下文切换的一部分执行 CLREX 指令不是必需的。
注:
上下文切换不是应用级操作。但是,此处包含此信息是为了完整描述独占操作。
B2.12.5 独占加载与独占存储指令的使用限制(Load-Exclusive and Store-Exclusive instruction usage restrictions)
独占加载和独占存储指令旨在作为一个指令对协同工作,例如 LDXP/STXP 对或 LDXR/STXR 对,作为仅包含单个独占加载和独占存储对的循环的一部分执行。
为了支持这些功能的不同实现,软件必须遵循以下给出的说明和限制。
以下说明描述了 LoadExcl/StoreExcl 指令对的使用,以表示表 B2-2 中所示的任何独占加载/独占存储指令对的使用。在此语境下,LoadExcl/StoreExcl 对由同一执行线程中的两条指令组成:
独占机制(exclusives)为执行的每个 PE 线程支持单个未完成的独占访问(single outstanding exclusive access)。架构通过不要求地址或大小检查作为 IsExclusiveLocal() 函数的一部分来利用这一点。如果 StoreExcl 的目标 VA 与同一执行线程中先前 LoadExcl 指令的 VA 不同,则行为可能是受约束的不可预测(CONSTRAINED UNPREDICTABLE),具有以下行为:
- StoreExcl 要么通过要么失败,StoreExcl 返回的状态值为未知(UNKNOWN),并且该 PE 的本地和全局监视器的状态为未知(UNKNOWN)。
注:
这意味着 StoreExcl 对于某些地址不匹配的 LoadExcl/StoreExcl 对实例可能通过,而对于其他地址不匹配的 LoadExcl/StoreExcl 对实例可能失败。- LoadExcl 访问的地址处和 StoreExcl 访问的地址处的数据为未知(UNKNOWN)。
这意味着软件只有在 LoadExcl 和 StoreExcl 使用相同的 VA 执行时,才能依赖 LoadExcl/StoreExcl 对最终成功。
独占加载和独占存储指令的实现可能要求,在任何执行线程中,StoreExcl 指令的事务大小(transaction size)与同一线程中先前执行的 LoadExcl 指令的事务大小相同。如果 StoreExcl 指令的事务大小与同一执行线程中先前 LoadExcl 指令的事务大小不同,则行为可能是受约束的不可预测(CONSTRAINED UNPREDICTABLE),具有以下行为:
- StoreExcl 要么通过要么失败,StoreExcl 返回的状态值为未知(UNKNOWN)。
注:
这意味着 StoreExcl 对于某些事务大小不匹配的 LoadExcl/StoreExcl 对实例可能通过,而对于其他事务大小不匹配的 LoadExcl/StoreExcl 对实例可能失败。- LoadExcl/StoreExcl 对使用的较大事务大小所对应的数据块(位于 LoadExcl/StoreExcl 对访问的地址处)为未知(UNKNOWN)。
这意味着软件只有在 LoadExcl 和 StoreExcl 具有相同的事务大小时,才能依赖 LoadExcl/StoreExcl 对最终成功。
LoadExcl 和 StoreExcl 指令的实现可能要求,在任何执行线程中,StoreExcl 指令访问的寄存器数量与同一线程中先前执行的 LoadExcl 指令相同。如果 StoreExcl 指令访问的寄存器数量与同一执行线程中先前 LoadExcl 指令不同,则行为是受约束的不可预测(CONSTRAINED UNPREDICTABLE)。因此,软件只有在访问相同数量的寄存器时,才能依赖 LoadExcl/StoreExcl 对最终成功。更多信息请参见”独占加载/独占存储访问不同数量寄存器时的受约束不可预测行为(CONSTRAINED UNPREDICTABLE behavior when Load-Exclusive/Store-Exclusive access a different number of registers)”。
独占加载和独占存储指令的实现可能要求,在任何执行线程中,由于 StoreExcl 指令引起的内存访问的标签检查属性(Tag Checked property)与先前 LoadExcl 指令的内存访问的标签检查属性相同,除非实现了 FEAT_MTE_STORE_ONLY 且先前 LoadExcl 仅因启用了仅存储标签检查(Store-only Tag Checking)而未进行标签检查。如果同一执行线程中 LoadExcl/StoreExcl 对的内存访问的标签检查属性不兼容,则行为可能是受约束的不可预测(CONSTRAINED UNPREDICTABLE),具有以下行为:
- StoreExcl 要么通过要么失败,StoreExcl 返回的状态值为未知(UNKNOWN)。
注:
这意味着 StoreExcl 对于某些此类 LoadExcl/StoreExcl 对实例可能通过,而对于其他此类 LoadExcl/StoreExcl 对实例可能失败。- LoadExcl/StoreExcl 对访问的地址处的数据为未知(UNKNOWN)。
这意味着软件只有在使用兼容的标签检查属性访问内存时,才能依赖 LoadExcl/StoreExcl 对最终成功。
如果未实现 FEAT_LSE,则仅当对于单个执行线程内的任何 LoadExcl/StoreExcl 循环,软件满足所有以下条件时,才保证 LoadExcl/StoreExcl 循环能取得前进进度(forward progress)。如果实现了 FEAT_LSE,则软件可通过满足所有以下条件,最大化单个执行线程内任何 LoadExcl/StoreExcl 循环取得前进进度的可能性:
- 在独占加载(Load-Exclusive)和独占存储(Store-Exclusive)之间,不得有任何显式内存效应(explicit memory effects)、软件预取(software prefetches)、直接或间接的系统寄存器写入、地址转换指令(address translation instructions)、缓存或 TLB 维护指令、异常生成指令、异常返回、ISB 屏障、间接分支(indirect branches)或带链接的分支指令(Branch with Link instructions)。
- 在返回失败结果的独占存储(Store-Exclusive)和重试相应的独占加载(Load-Exclusive)之间:
- 不得有对 StoreExclusive 所访问的独占预留粒度(Exclusives reservation granule)内任何地址的存储或 PRFM 或 RPRFM 指令。这包括这些地址的 VA 别名(VA aliases)。
- 不得有对 StoreExclusive 所访问的独占预留粒度(Exclusives reservation granule)内任何地址的、使用不同 VA 别名的加载或预取。
- 不得有任何其他对任何其他地址的独占存储(Store-Exclusive)指令。
- 不得有任何直接或间接的系统寄存器写入、地址转换指令、缓存或 TLB 维护指令、异常生成指令、异常返回、间接分支或带链接的分支指令。
- 所有加载和存储必须针对大小不超过 512 字节的连续虚拟内存块(contiguous virtual memory)。
独占监视器(Exclusives monitor)可以在没有任何应用相关原因的情况下随时被清除,前提是这种清除不会被系统性地重复以至于阻止至少一个正在访问该独占监视器的线程在有限时间内取得前进进度。但是,如果另一个线程在紧循环(tight loop)中重复执行以下任何操作,则 LoadExcl/StoreExcl 循环可能无法取得前进进度:
- 对独占监视器覆盖的 PA 执行存储。
- 以写入意图对独占监视器覆盖的 PA 执行预取。
- 对独占监视器覆盖的 PA 执行数据缓存清理(data cache clean)、数据缓存无效(data cache invalidate)或数据缓存清理并无效(data cache clean and invalidate)指令。
- 执行指令缓存全部无效(instruction cache invalidate all)指令。
- 对独占监视器覆盖的 PA 执行按 VA 的指令缓存无效(instruction cache invalidate by VA)指令。
- 对独占监视器覆盖的 PA 执行 TLB 维护。
实现可以受益于在单个执行线程中将 LoadExcl 和 StoreExcl 操作保持紧密相邻。这可以最小化在 LoadExcl 指令和 StoreExcl 指令之间清除独占监视器状态的可能性。因此,为了获得最佳性能,Arm 强烈建议在单个执行线程中,LoadExcl 和 StoreExcl 指令之间的限制为 128 字节。
架构为可被标记为独占的独占预留粒度(Exclusives reservation granule)设置了 2048 字节的上限。出于性能原因,Arm 建议通过独占访问访问的对象应分隔一个独占预留粒度的大小。这是一个性能指导原则,而非功能性要求。
在获取数据中止异常(Data Abort exception)后,独占监视器的状态为未知(UNKNOWN)。
对于由 LoadExcl/StoreExcl 对访问的内存位置,如果 StoreExcl 指令的内存属性与同一执行线程中先前 LoadExcl 指令的内存属性不同,则行为是受约束的不可预测(CONSTRAINED UNPREDICTABLE)。如果这是由于在 LoadExcl 指令和 StoreExcl 指令之间访问地址的转换发生变化所致,则受约束的不可预测行为如下:
- StoreExcl 要么通过要么失败,StoreExcl 返回的状态值为未知(UNKNOWN)。
注:
这意味着 StoreExcl 对于某些内存属性已更改的 LoadExcl/StoreExcl 对实例可能通过,而对于其他内存属性已更改的 LoadExcl/StoreExcl 对实例可能失败。- StoreExcl 访问的地址处的数据为未知(UNKNOWN)。
注:
本列表中的另一个要点涵盖了 LoadExcl/StoreExcl 对因使用指向相同 PA 但具有不同属性的不同 VA 而导致内存属性不同的情况。数据或统一缓存无效(invalidate)、清理(clean)或清理并无效(clean and invalidate)指令对处于独占访问状态的本地或全局独占监视器的影响是受约束的不可预测(CONSTRAINED UNPREDICTABLE) 的,该指令可能清除监视器,也可能使其保持独占访问状态。对于基于地址的维护指令,这也适用于与执行缓存维护指令的 PE 处于相同可共享域(由被维护地址的可共享域决定)中的其他 PE 的监视器。
注:
Arm 强烈建议实现应确保 PE 在一个安全状态(Security state)下使用此类维护指令不会导致对另一个安全状态中的 PE 造成拒绝服务(denial of service)。如果在 LoadExcl 指令和 StoreExcl 指令之间更改了 VA 到 PA 的映射,并且该更改是使用”在更新转换表条目时使用先断开再建立(break-before-make)”序列执行的,则如果在 StoreExcl 之后对同一 PA 进行了另一次写入,并且该另一次写入是在旧转换被正确无效(invalidated)并且该无效已被正确同步之后执行的,则 StoreExcl 将不会通过其监视器检查。
注:
Arm 预期,在许多实现中,要么:- TLB 无效化将清除本地或全局监视器。
- 将在 LoadExcl 和 StoreExcl 之间检查 PA。
PE 所访问地址的独占访问状态可能会因为由另一个 PE 对同一 PA 执行的 PRFM PST* 或 RPRFM 指令而丢失。这意味着对某个内存位置以非常高的频率重复 PRFM PST* 或 RPRFM 访问可能会阻碍另一个 PE 的前进进度。
如果实现了 FEAT_MTE2,并且如果标签未检查(Tag Unchecked)的独占存储指令不会执行存储并返回状态值 1,则以下情况是受约束的不可预测(CONSTRAINED UNPREDICTABLE) 的:
- 该指令是标签已检查(Tag Checked)访问,
- 该指令是标签未检查(Tag Unchecked)访问。
更多信息请参见”内存标记扩展(The Memory Tagging Extension)”。
注:
在来自多个 PE 的反复争用 LoadExcl/StoreExcl 指令序列的情况下,实现必须确保至少有一个 PE 取得前进进度(forward progress)。
B2.12.5.1 独占加载/独占存储访问不同数量寄存器时的受约束不可预测行为(CONSTRAINED UNPREDICTABLE behavior when Load-Exclusive/Store-Exclusive access a different number of registers)
如本节所述,实现可以要求独占加载/独占存储指令对的指令访问相同数量的寄存器。在此类实现中,这意味着如果在单个执行线程中出现以下任一情况,则行为是受约束的不可预测(CONSTRAINED UNPREDICTABLE) 的:
- 一个两个 32 位量的 LDXP 指令后跟一个在同一地址的一个 64 位量的 STXR 指令。
- 一个一个 64 位量的 LDXR 指令后跟一个在同一地址的两个 32 位量的 STXP 指令。
在这些情况下,受约束的不可预测行为必须是以下之一:
- STXP 或 STXR 指令生成一个外部数据中止(external Data Abort)。
- STXP 或 STXR 指令生成一个由实现定义(IMPLEMENTATION DEFINED) 的 MMU 故障,使用 ESR_ELx.DFSC = 0b110101 的数据中止故障状态码(Data Abort Fault status code)报告。
- STXP 或 STXR 指令始终失败,返回状态值 1。
- STXP 或 STXR 指令始终通过,返回状态值 0。
- 该 STXP 或 STXR 指令具有与先前 LDXR 或 LDXP 指令使用相同大小和数量的寄存器时本应具有的相同通过或失败行为。
B2.12.6 自旋锁中 WFE 和 SEV 指令的使用(Use of WFE and SEV instructions by spin-locks)
Armv8 提供了等待事件(Wait For Event)、发送事件(Send Event)和本地发送事件(Send Event Local)指令,即 WFE、SEV 和 SEVL,它们有助于降低因 PE 反复尝试获取自旋锁(spin-lock)而导致的功耗和总线争用。这些指令可以在应用级使用,但对它们功能的完整理解取决于对异常的系統级理解。它们在”等待事件(Wait for Event)”中进行了描述。然而,在 Armv8 中,当 PE 的全局监视器从独占访问状态变为开放访问状态时,会生成一个事件(event)。
注:
这等效于在监视器状态已更改的 PE 上发出 SEVL 指令。它消除了在清除自旋锁后在自旋锁代码中包含 SEV 指令的需要。
译者注:
- 本节中”Exclusives reservation granule”统一译为”独占预留粒度”,指 Load-Exclusive 指令所标记的最小内存块大小,范围由实现定义,为 4-512 个字(即 16-2048 字节)。
- “Local monitor”和”Global monitor”分别译为”本地监视器”和”全局监视器”,两者共同构成了 Arm 架构中独占访问机制的完整监控体系。
- “Exclusive Access state”和”Open Access state”分别译为”独占访问状态”和”开放访问状态”,用于描述监视器的两种状态。
- “CONSTRAINED UNPREDICTABLE”译为”受约束的不可预测”,是 Arm 架构中的专业术语,指行为的結果在有限的几种可能性之中,但具体是哪种由实现决定。
- 图 B2-4 和图 B2-5 为状态机图,在文本中无法以图形方式呈现,相关描述已在各节文字中详细说明。
- B2.12.5 节中关于 LoadExcl/StoreExcl 对的使用限制较为复杂,核心要点是:同一线程中的 LoadExcl 和 StoreExcl 应使用相同的 VA、相同的事务大小、相同的寄存器数量,并且两者之间应尽量紧凑,以确保独占访问的成功率。